[2019 CVPR] Joint Discriminative and Generative Learning for Person Re-identification
Table of content (full-version) [paper] [github]
Summary
- Joint learning (end-to-end) (첫 시도)
- Data generation(generative module) appearance/structure 구분하여 인코딩
- Re-id learning(discriminative module) appearance와 structure에 대한 심화학습
Motivation
- Re-ID에서 대표적인 문제: cross camera 사이의 intra class variation
- 기존 방법: data augmentation을 위한 여러가지 generative pipeline
- 문제점: Generative pipeline은 보통 discriminative re-id learning 단계와 분리되어 있음
- 해결책: 이 논문에서는 생성된 데이터들을 더 잘 이용함으로써 학습된 re-id embedding을 향상시키기 위해서 re-id learning과 data generation을 동시에 학습하는 end-to-end 구조를 제안한다. (처음)
- Unconditional GAN과 다른점: more controllable generation with better quality
- Pose-guided GAN과 다른점: 가지고 있는 데이터셋의 pose-variation을 이용하기에 추가적인 보조 데이터(3d pose)가 필요하지 않음
Architecture
[전체 프레임워크]
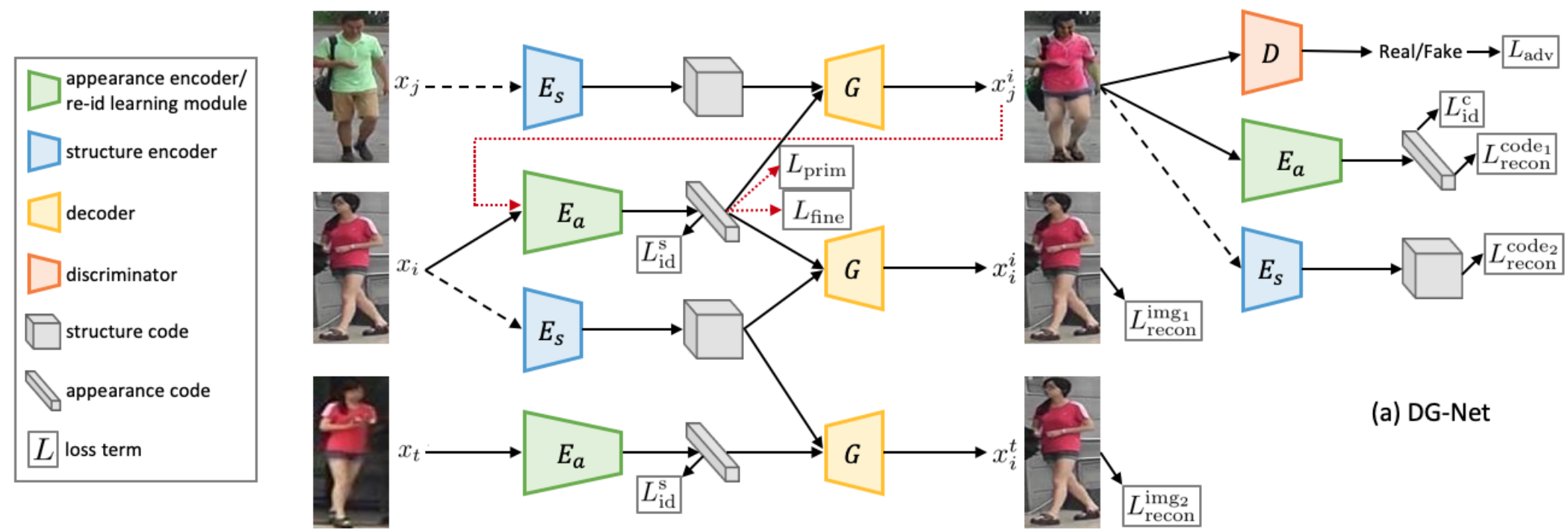
Generative module
- 사람의 영상을 appearance()와 structure()로 분리하여 인코딩 후 디코딩 (a/s변경가능)
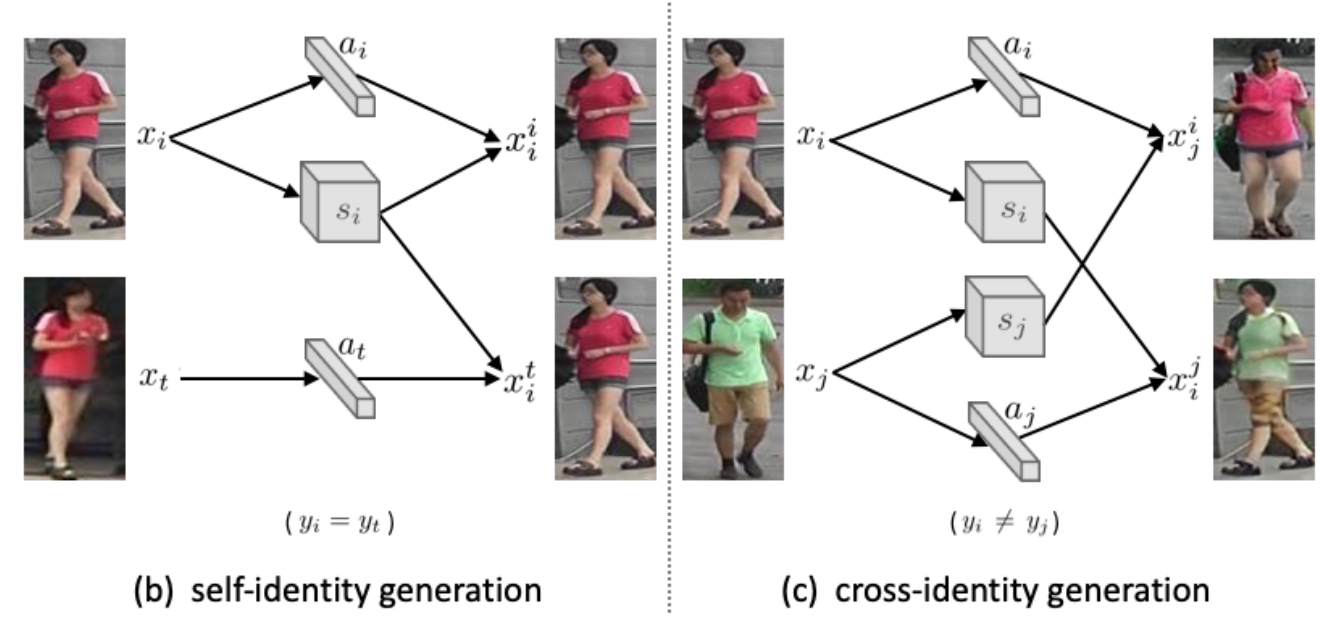
- Self-identity generation: generator를 regularization하는 역할
- - 하나의 영상에서 인코딩된 와 로 생성된 영상과 와의 복원오차 (L1)
- - (같은 ID지만 다른영상)와 로 생성된 영상과 와의 복원오차 (L1)
- - 입력 영상에 appearance로 인코딩된 특징벡터의 identification loss
- Cross-identity generation: a와 s를 명확히 구분하여 생성된 이미지를 제어 가능하게 하고 실제 데이터 분포에 맞게 생성
- - 를 appearance 인코딩 했을 때 structure에 상관없이 의 특징벡터 복원 (L1)
- - 를 structure 인코딩 했을 때 appearance에 상관없이 의 특징벡터 복원 (L1)
- - 새롭게 생성된 영상에 appearance로 인코딩된 특징벡터의 ID loss (의 레이블)
- - 입력 영상과 생성된 영상 를 D에 통과 했을 때 각각 real/fake 결과가 나오도록
- Discussion
- 기존 방법들은 random noise나 pose factor를 사용하는 반면에 명확하게 a/s 코드를 분리하여 생성한다.
- a/s로 분리된 latent vector가 설명 가능하다.
- 만큼의 영상을 생성할 수 있다.
[Generative module]
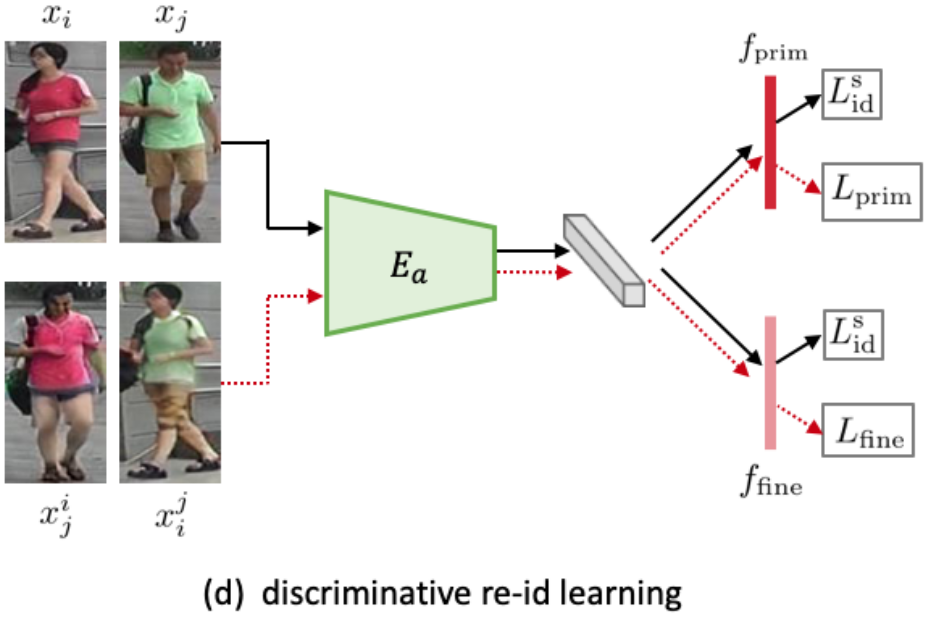
Discriminative module
- 생성된 영상을 실제 학습 데이터셋과 부합시키면서 어떻게 잘 학습시킬지에 대한 모듈
- Primary feature learning: focusing on structure-invariant clothing information
- Teacher-student type supervision with dynamic soft labeling을 채택
(student가 teature의 확률분포를 따라가게끔 KL divergence 최소화)
- Teacher: baseline CNN과 ID loss로 기존의 training set 학습 후 생성된 영상 에 에 대한 one-hot vector를 할당하는 것이 아닌 teacher에 의한 soft label을 채택
- Student: discriminative module(즉, 기존 학습셋과 생성된 영상 모두로 학습된 모듈)에 의한 예측 값
- Teacher-student type supervision with dynamic soft labeling을 채택
(student가 teature의 확률분포를 따라가게끔 KL divergence 최소화)
- Fine-grained feature mining: focusing on appearance-invariant structural cue
- 기존에는 를 로 분류했지만 반대되는 성격을 얻기 위해 로 분류
- 따라서 appearance(보통 옷 색깔)에 무관하며 fine-grained id-related attributes (hair, hat, body size, bad)등이 학습
- 기존의 방법들은 수동으로 attribute를 주거나 hard sampling policy를 수행한 반면, 미묘한 ID 특성에 주의하는 학습법을 통해 추가적인 identity supervision을 주입한다.
- Discussion
- 실제로 re-ID testing 때 사용할 특징벡터는 두 모듈의 결과를 concat해서 사용 (512+512 dim)
- Appearance encoder를 Generative module과 공유
- 해당 loss는 generative module이 어느정도 수렴한 다음에 같이 학습
[Discriminative module]
Experimental results
- Image generation
[다른 방법들과 image generation 결과 비교]

[Appearance와 structure 융합 예시]

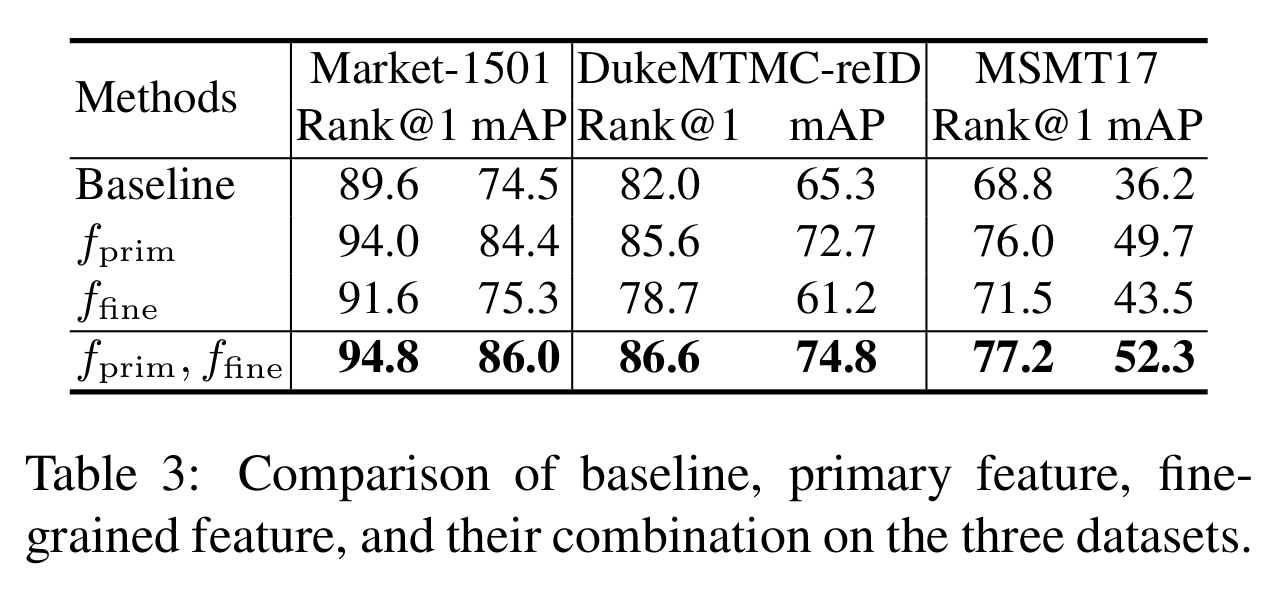
- Ablation study
[Ablation study (image generation)]

[Ablation study (discriminative module)]
- Performance
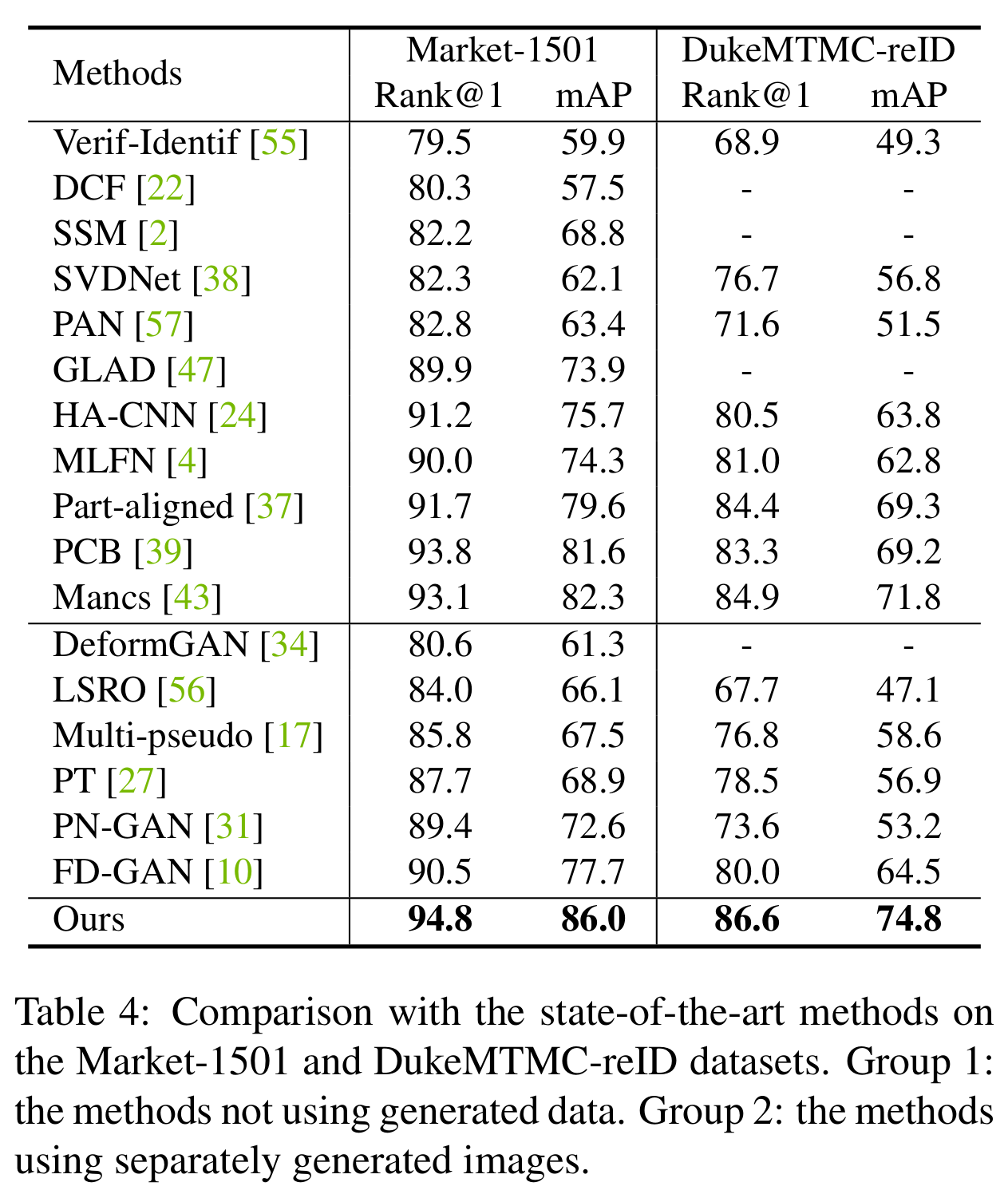
[Re-ID performance (Market-1501, DukeMTMC-reID)]
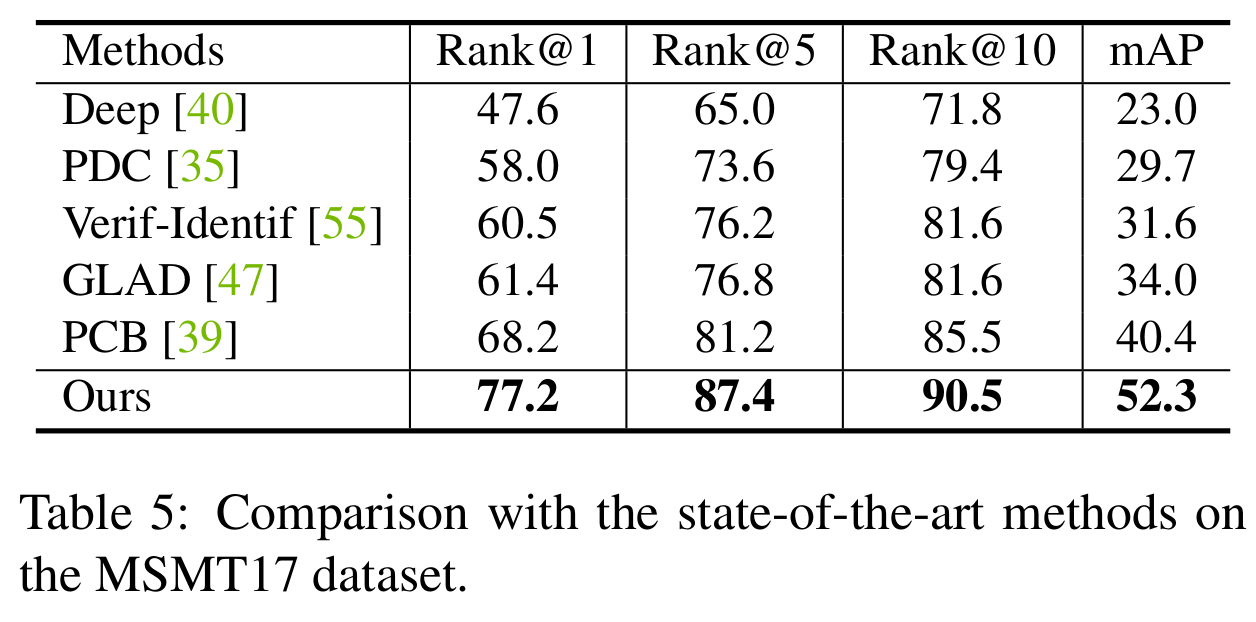
[Re-ID performance (MSMT17)]
- Failure case
- 단색옷이 많아서 텍스쳐 로고 잘 반영이 안된다.
[Failure case]

Comments
- 색만 입힌 느낌이 난다. 텍스쳐가 잘 안잡히는 느낌
References
[1] Zheng, Zhedong, et al. “Joint discriminative and generative learning for person re-identification.” arXiv preprint arXiv:1904.07223 (2019).