[2019 CVPR] Learning to Reduce Dual-level Discrepancy for Infrared-Visible Person Re-identification
Table of content (full-version) [paper]
Summary
- Infrared-Visible person RE-ID (IV-REID) 분야
- 문제점: appearance(APP) discrepancy + modality(MOD) discrepancy
- 기존방법: feature-level contraint 사용하여 APP+MOD 차이를 동시에 감소 시도
- 논문방법: Dual-level Discrepancy Reduction Learning (DDRL) 는 두 개의 discrepancy를 분리
- Image-level sub-network: RGB IR 영상 변환으로 서로 다른 MOD를 가진 영상에 대한 표현을 통합
- Feature-level sub-network: 통합된 multi-spectral 영상을 가지고 feature embedding을 통해 남은 APP discrepancy를 감소
- 두 개의 sub-network를 직렬로 jointly 학습하여 dual-level discrepancy를 협동적 + 조심스럽게 감소
- 논문을 읽기 쉽게 잘썼음
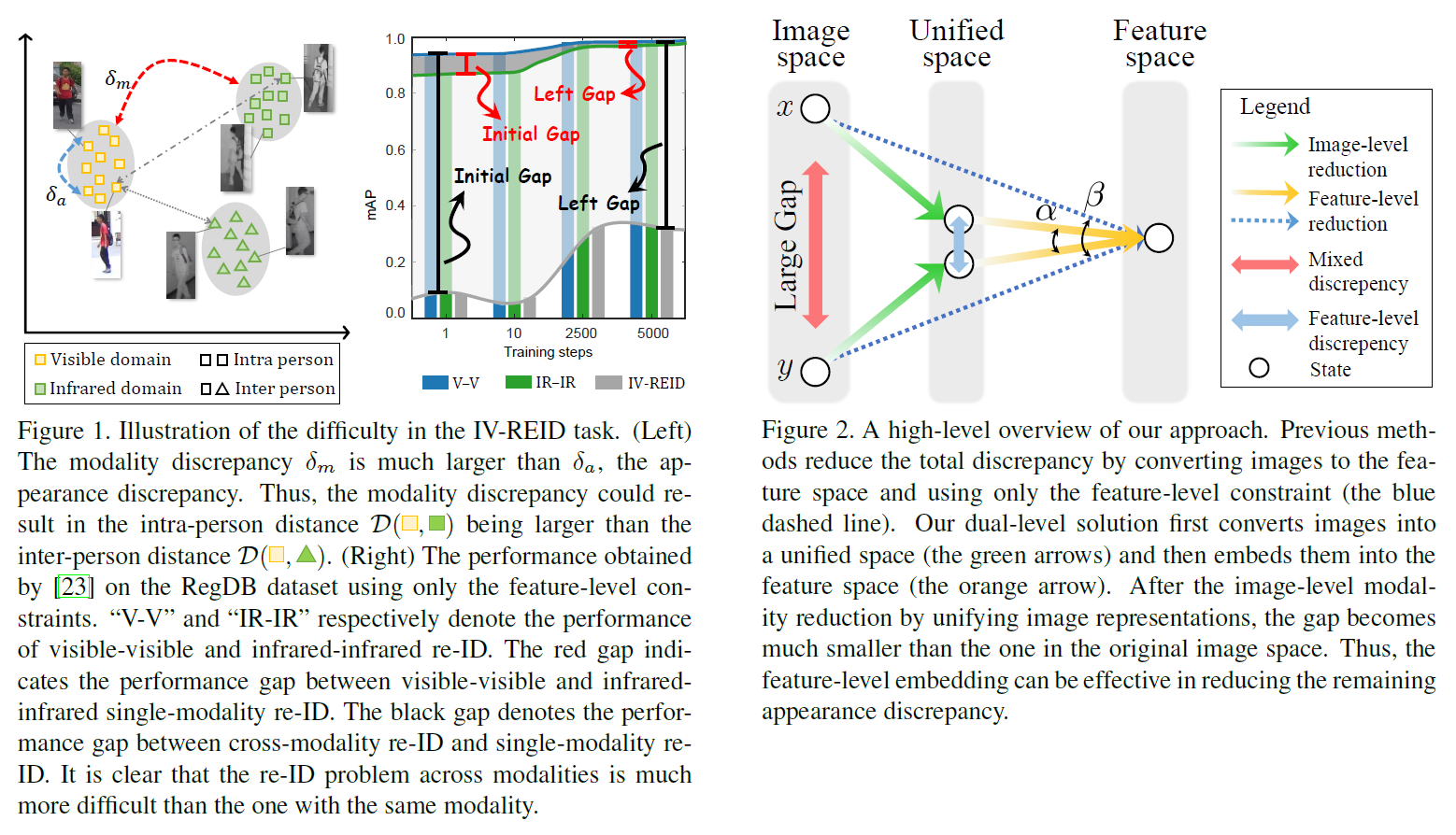
Motivation
- IR-REID 에서 Intra-person 사이의 간격이 Inter-person 사이의 간격보다 오히려 커서 성능이 낮음
- 이를 feature-space에서 한 번에 조정하기 힘듦
- 영상 변환을 통해 unified space로 옮긴 다음에 feature-space에서 남은 appearance의 차이를 더 줄임
[Motivation]
Architecture
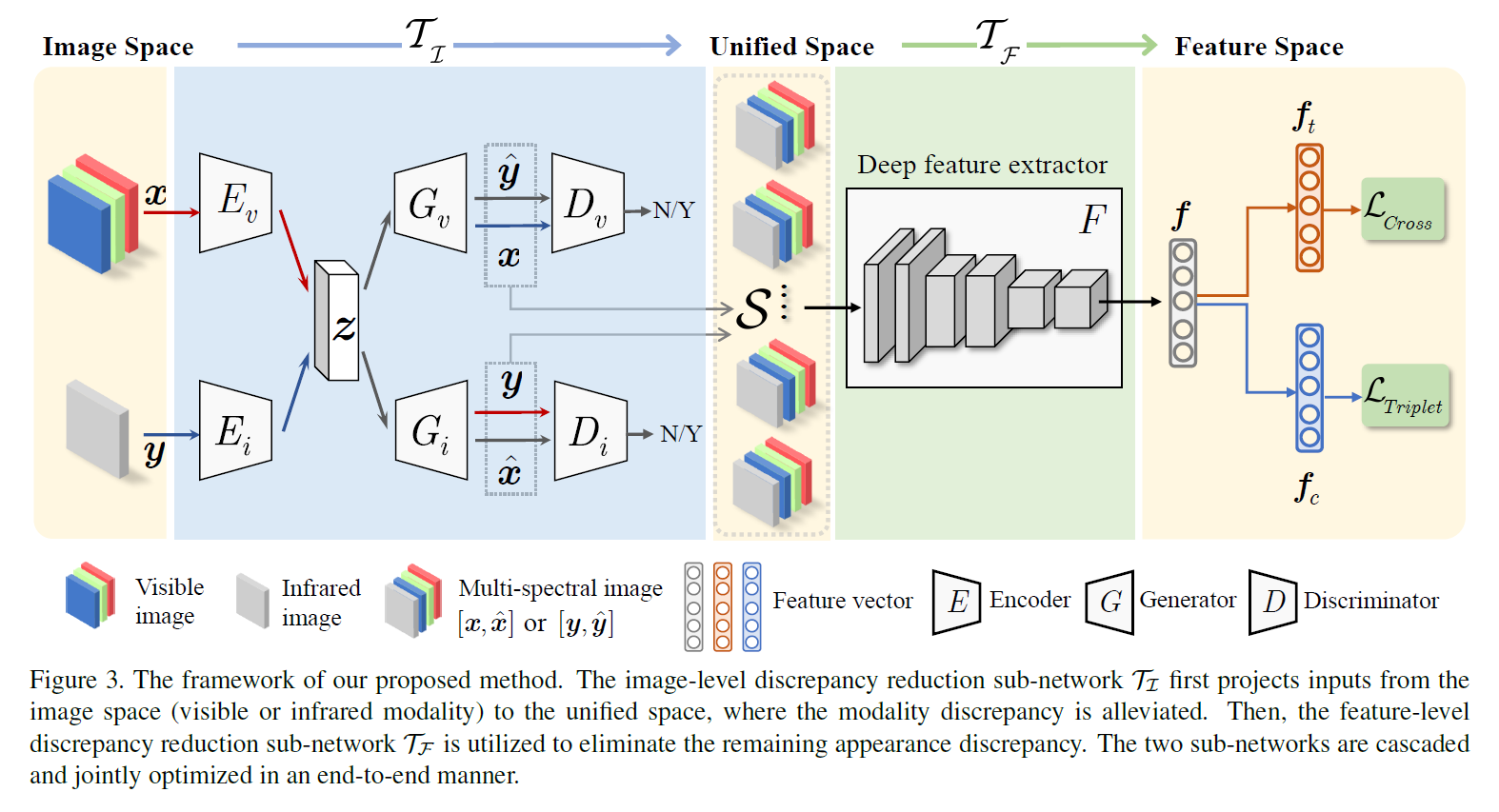
Image-level discrepancy reduction
- Style disentanglement (): VAE 이용(KL loss + self recons loss), RGB / IR 영상 따로 Enc, Dec 존재
- Domain specific image generation (): GAN 이용(adversarial loss),
- Cycle-consistency (): cross reconstruction loss()
- Modality unification: RGB, IR에서 영상을 합치지 않고 multi-spectral image (6dim2)를 생성, 각 batch마다 sample set(여러 장의 multi-spectral image)을 발생
- Objective for training: 6개의 loss를 학습하기 위해서 그리고 multi-spectral 영상을 생성하기 위해서 RGB 와 IR버전 , IR 와 RGB버전 가 필요하다. Query-gallery 영상을 포함한 모든 이미지를 이런 방식으로 나타내어 학습하고 이 때 modality discrepancy가 크게 감소된다.
Feature-level discrepancy reduction
- ResNet-50사용, last FC-1000 FC-1024로 대체
- FC-1024 이후에 두 개의 독립적인 FC-128(for triplet loss), FC-(for cross-entropy loss)로 분할
[전체 프레임워크]
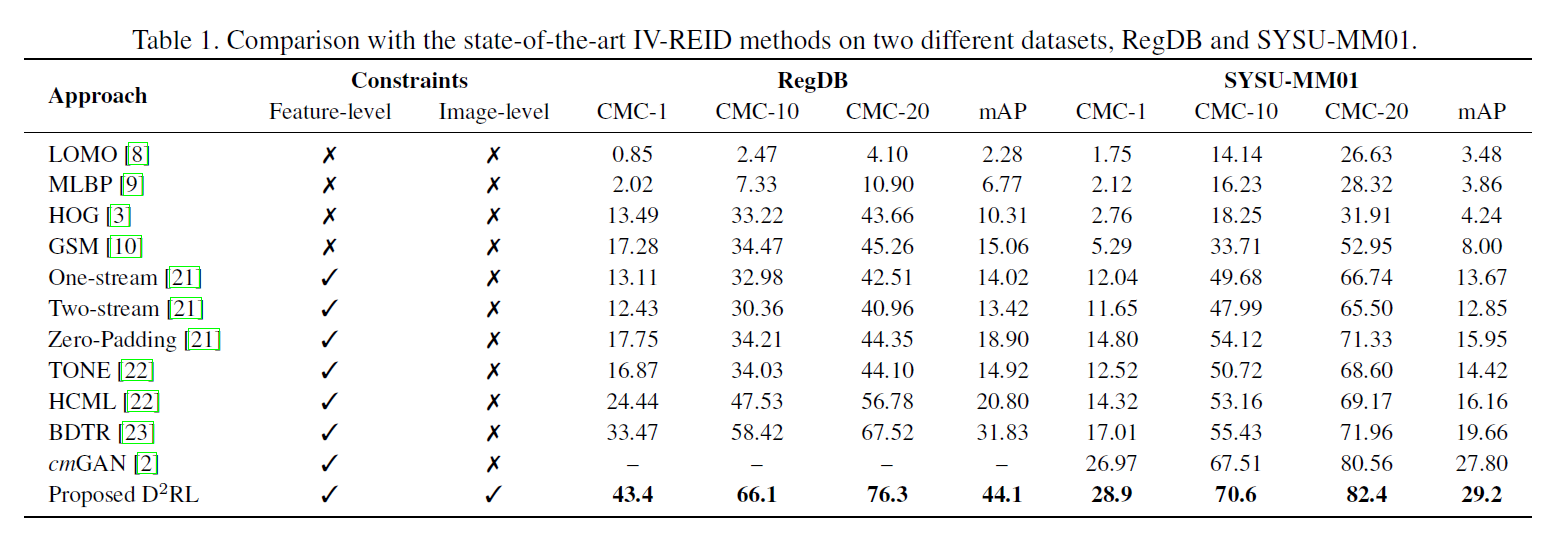
Experimental results
- Dataset
- RegDB: 412명, 사람마다 10장의 RGB, 10장의 IR (FIR), 무작위로 섞어서 반 나눔
- SYSU-MM01: 491명, 카메라 6대, 실내/실외, 학습(22258 RGB, 11909 IR)
- IR-REID의 실험 프로토콜: query가 선택되면 gallery의 modality는 query와 항상 다르게 설정
- Implementation detail
- IR, RGB 모두 3channel로 이용
- Image-level sub-network [2], feature-level sub-network [3] 이용
[IV-REID 성능 비교]
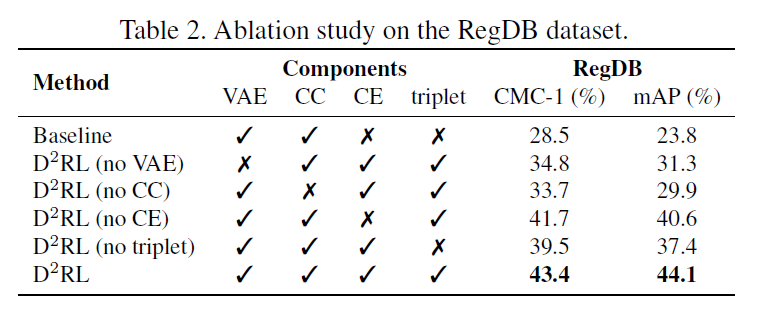
- Ablation study
- Baseline은 multi-spectral image 합치는 것 없이 바로 특징 뽑아서 사용
- Cycle consistency가 가장 큰 효과
[Ablation study]
- Discussion
- BDTR은 feature-level 방식 / 이 논문은 dual-level 방식
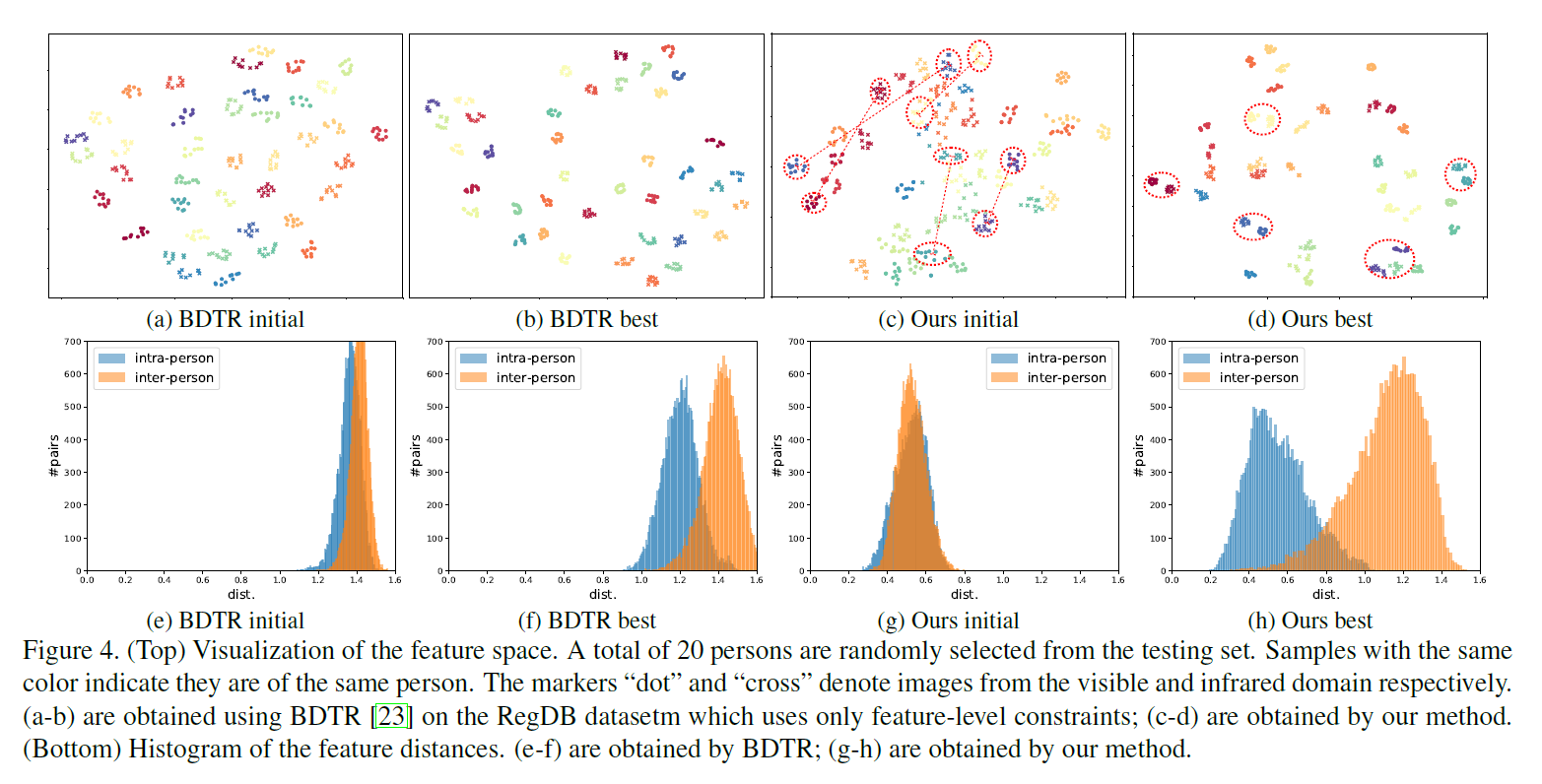
- Test sample은 RegDB에서 20명의 사람
- BDTR은 학습이 진행될 수록 single-modality intra-person 특징분포가 가까워짐 / cross-modality intra-person은 변화 없음
- Ours는 학습이 진행될 수록 single-modality & cross-modality intra-person 특징분포가 가까워짐
- Feature distance histogram를 볼 때, ours가 BDTR보다 inter-person / intra-person 쌍이 분리됨
- 즉, 효과적으로 feature embedding이 된 것
[Intra-person, inter-person의 feature-space distribution]
- Image-level 변환 결과
- 6번째 줄 color distortion 발생
- 최종목표가 좋은 영상 변환결과를 얻는 것은 아니다 (좋은 retrieval(re-id) 결과를 가져오면 된다.)
[Image-space 변환결과]

- Failure case
- Image-level modality unification이 잘 안되어서 발생한 문제들
[Failure case]

- Extra experiments
- Modality unification option: visual, infrared보다 multi-spectral의 성능이 높다
- Joint learning: separate learning보다 성능이 높다
- Sub-network 사이의 balance: 적절한 밸런스가 중요. 영상 변환같은 경우 modality 차이를 줄여주지만 noisy 결과를 불러올 수 있음
References
[1] Wang, Zhixiang, et al. “Learning to Reduce Dual-level Discrepancy for Infrared-Visible Person Re-identification.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Vol. 2. No. 3. 2019.
[2] https://github.com/mingyuliutw/UNIT
[3] https://github.com/Cysu/open-reid