[2019 CVPR] Re-Identification with Consistent Attentive Siamese Networks
Table of content (full-version) [paper]
Summary
[요약]
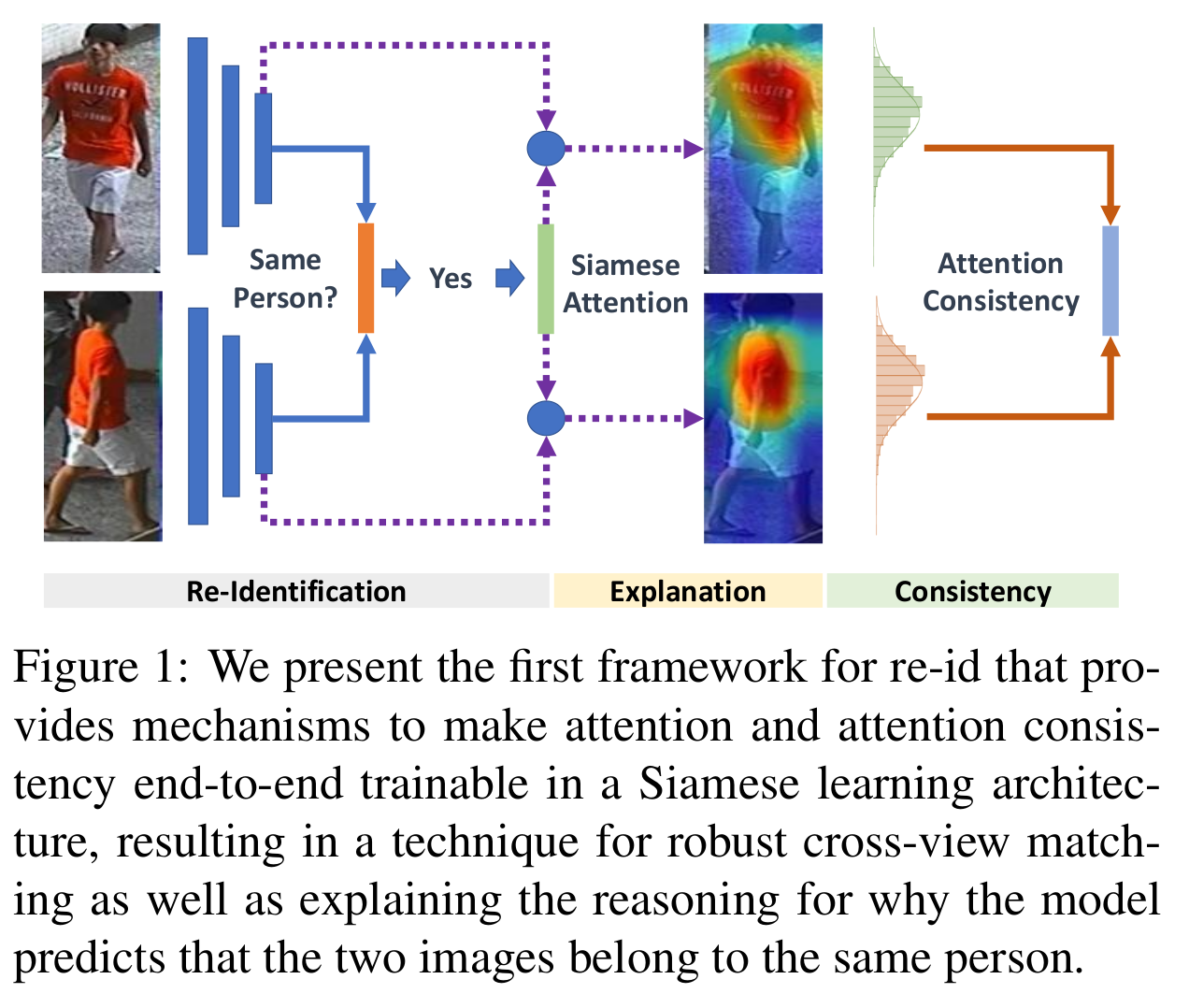
- 주요 이슈: 강인한 cross-view matching을 위해 spatial localization과 view-invariant representation learning
- Consistant Attentive Siamese Network (CASN) 제안 (attention-driven Siamese learning)
- Attention으로 별다른 supervision 없이 identity label만 이용
- 같은 사람 영상간의 attention consistency를 강요하는 명확한 메커니즘
- Attention consistency과 Siamese learning을 통합
- Siamese 네트워크의 예측의 원인을 설명해줄 수 있다.
Architecture
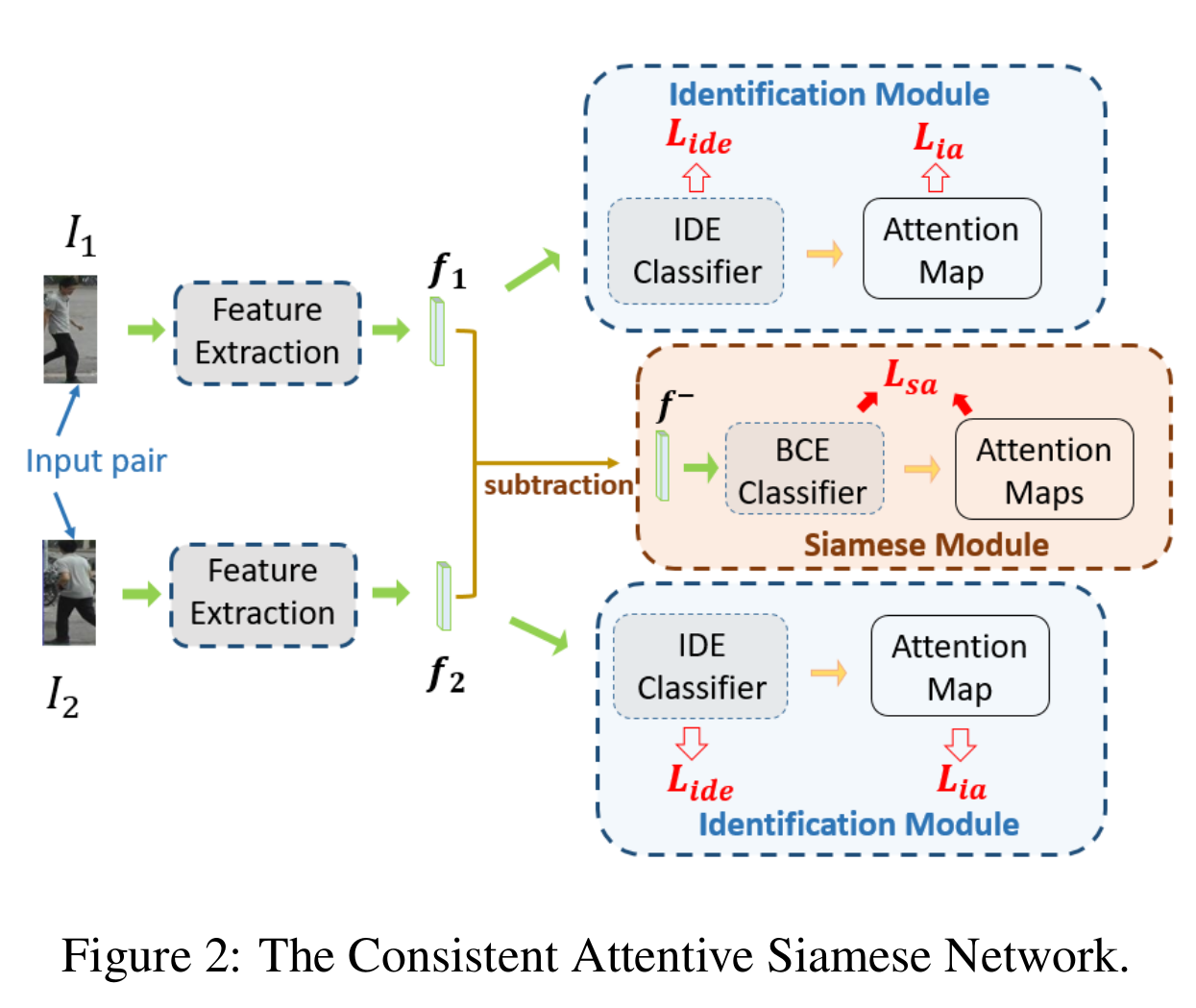
Overall framework (CASN)
- Identification module: IDE + attention map (Identity만 가지고 명확한 attention guide를 준다. 정확한 spatial localization 가능)
- Siamese module: 같은 사람에 대한 attension consistency를 강요, 강인한 갤러리 매칭을 위한 view-invariant feature representation 학습
[전체 프레임워크]
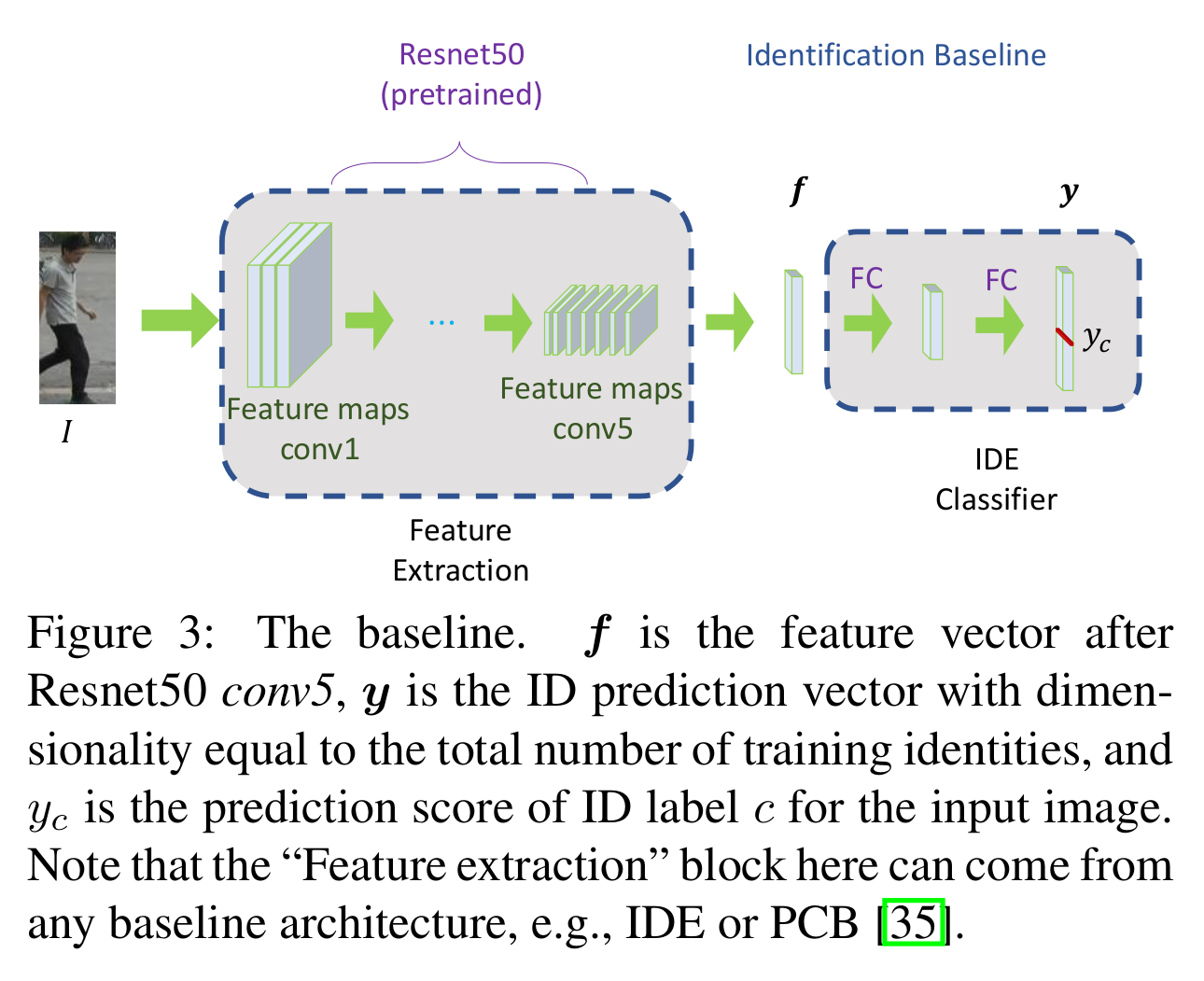
Identification module
- 기본적으로 IDE 사용 (ResNet50, pretrained ImageNet - conv1conv5, 2 fc layers, PCB 대체가능, multi-class cross-entropy loss)
- Identification attention
- 기본: [2]의 프레임워크 사용, identity만으로 spatially attentive region을 발생하도록
- 추가: 분류기가 예측한 ID class에 대해서 Grad-GAM에서 가장 강하게 영역(soft-mask)을 원본 영상에서 제외한 뒤, 이를 다시 분류했을 때 해당 아이디를 예측할 확률이 줄어들도록 학습 (즉, 일부 특징적인 영역만 보던 IDE가 사람의 모양 전반적인 것을 보기 시작 - 정확한 spatial localization)
- 문제점: 같은 사람의 다른 영상에서도 동일한 attention이 보장되지 않음. cross-camera에서 identity에 불변한 표현이 학습되지 않음. 분류 이후에 후처리하는 과정이 inference에는 적합하지 않음
[Identification module]
[Attention map with identification loss]

Siamese module
- Binary classification (BCE)
- 두 영상에서 추출된 특징의 차이를 이용하여 binary closs-entropy (BCE) classification 수행 (same / different)
- Classification에 대한 obj를 정한 이유는 attention 주는 방식이 GradCAM 기반이기 때문
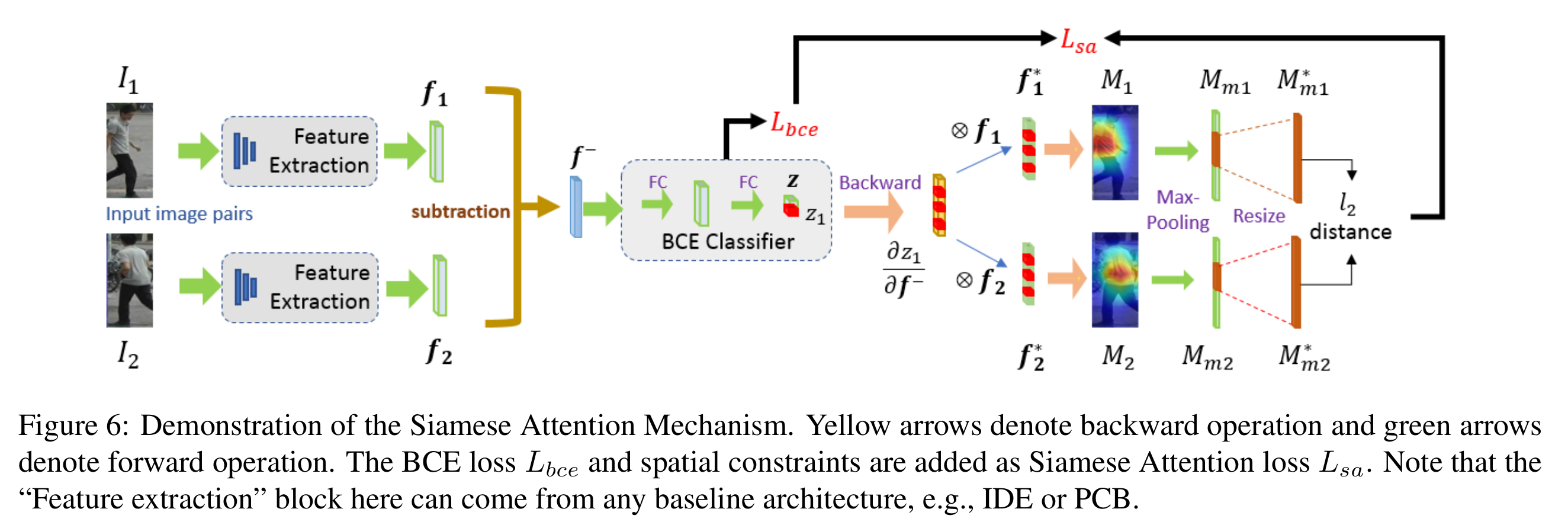
- Siamese attention mechanism
- Identification attention의 문제점을 해결하기 위해서 명확하게 attention consistency를 제공하는 siamese attention mechanishm 도입
- 먼저 BCE classifier의 예측값이 0보다 큰 (same이라고 판단하는) 원소들을 1로, 아닌 것을 0으로 하는 indicator vector를 계산 한다.
- 다음으로 이러한 indicator vector를 각 특징벡터와 dot product를 수행 하여 를 구하고, 이 값을 마지막 conv layer의 feature map에 편미분을 하여 channel importance map을 계산하고 grad-CAM처럼 이를 통해 attention map 을 계산한다.
- 이 attention map에서 수평으로 max pooling을 적용하여 를 계산하고 일정 threshold 이상인 부분을 resize하여 L2-distance를 수행한다.
- 이 loss는 positive pair는 같은 attention consistency를 갖고 negative pair는 다르게 갖도록 유도한다. (localization statistics)
[Siamese module]
[Attention map with BCE loss]
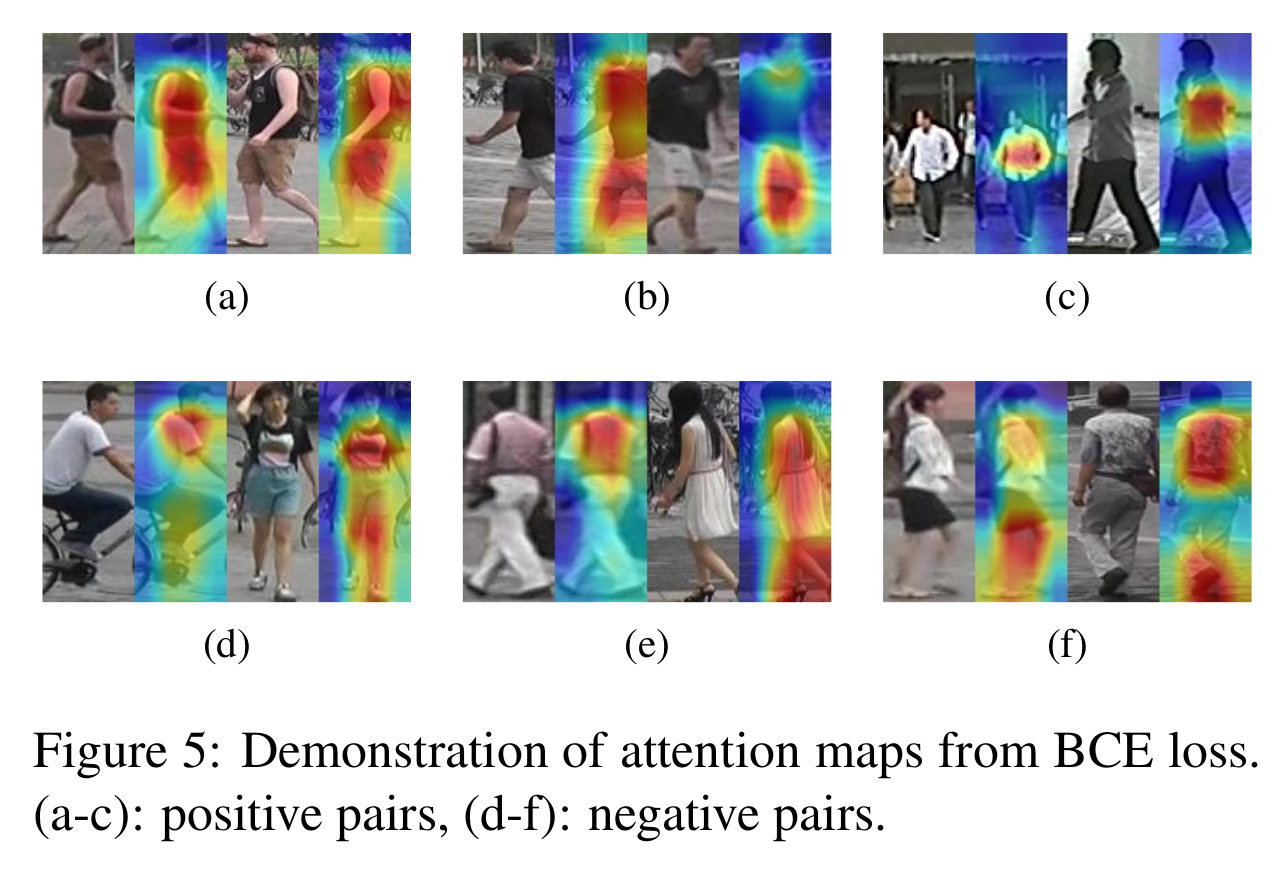
Experimental results
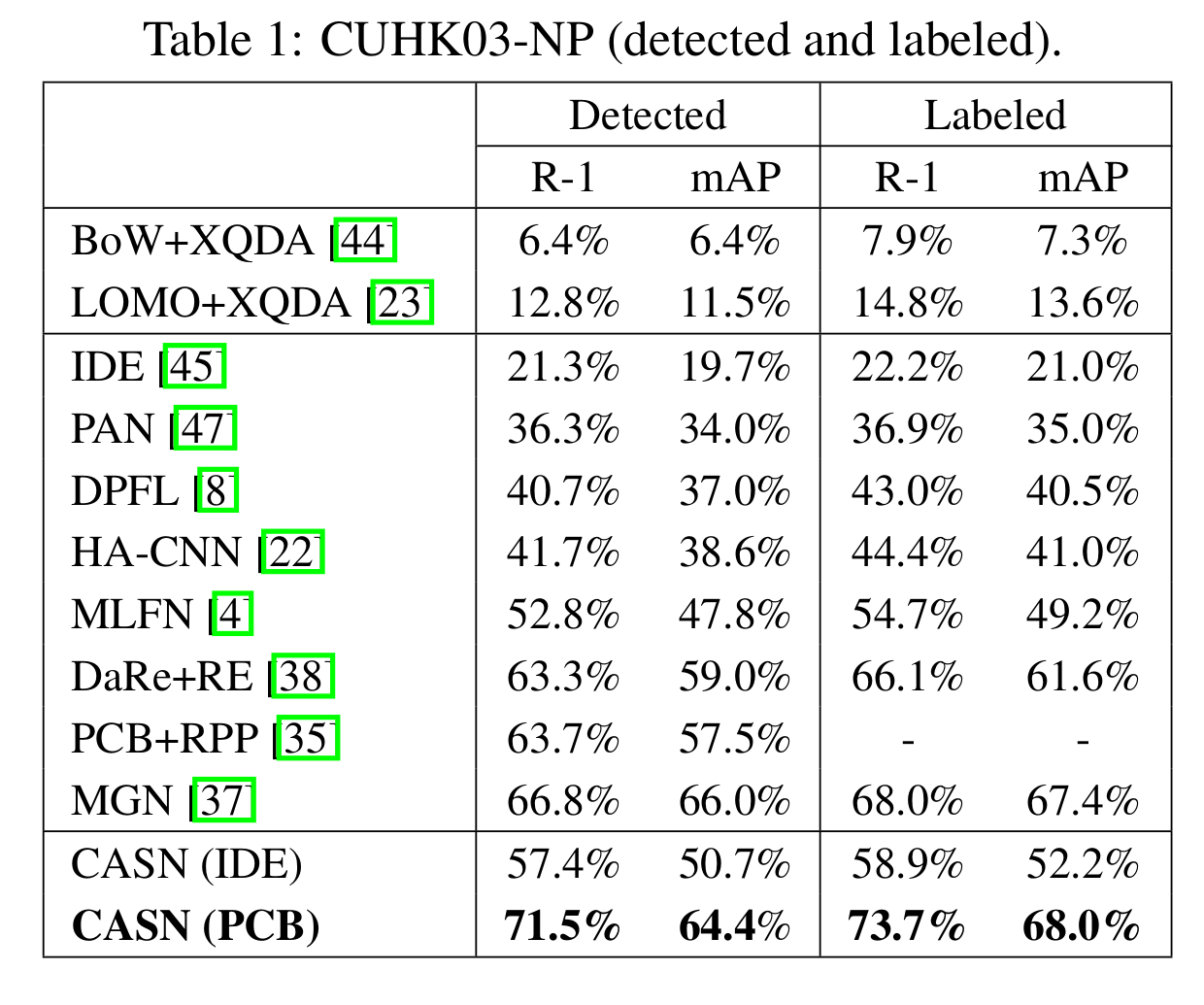
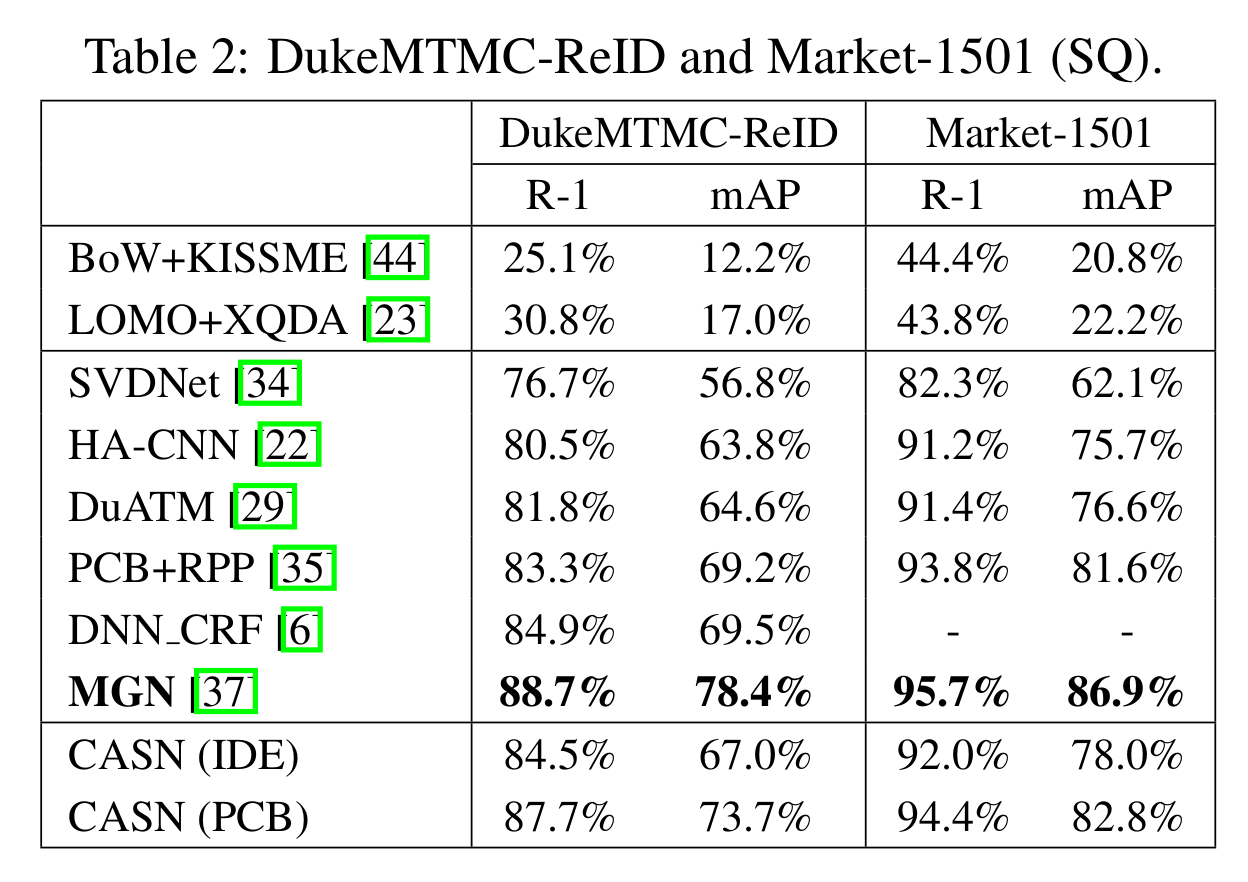
- Re-ID 성능
- 이 논문의 방식이 다른 attention module 방식보다 높은 성능을 보임
[Re-ID 성능 (CUHK03-NP)]
[Re-ID 성능 (DukeMTMC-ReID and Market-1501)]
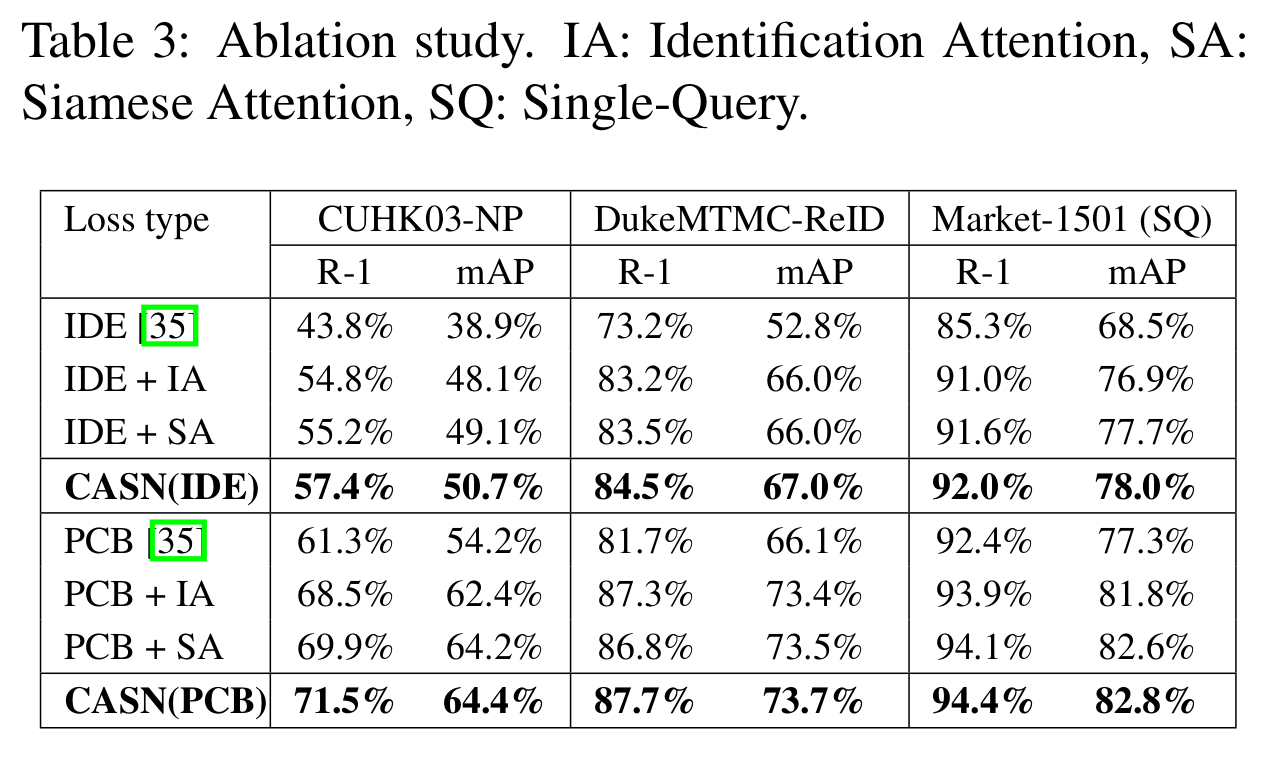
- Ablation study
- 모든 데이터셋에 대해서 IA, SA, both를 사용할 수록 성능이 향상됨을 보임
[Ablation study (수치)]
[Ablation study (attention map)]

Comments
- View-invariant representation learning을 설계했다고는 하지만, failure case에서는 view에 취약점을 보임
- 수직적으로 보는 attention은 중요하지 않나?
References
[1] Zheng, Meng, et al. “Re-Identification with Consistent Attentive Siamese Networks.” arXiv preprint arXiv:1811.07487 (2018).