[2019 CVPR] End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image
Table of content (short-version) [paper]
Summary
[Time-lapse video 예시]

- Outdoor 이미지 하나를 가지고 time-lapse 동영상을 만드는 end-to-end 방법
- Multi-frame multi-domain 방식
- C-GAN을 기반으로 time을 condition으로 넣어 multi-frame joint generation을 수행
- 분포가 다른 두 데이터셋(AMOS, TLVDB)을 이용하여 강인한 multi-domain 학습
- 다른 방법에 비해서 reference video를 요구하지 않으며, timestamp label을 변수로 활용 가능
Architecture
Dataset
- AMOS dataset: [장] 많은 장면 포함 / [단] 낮은 퀄리티
- TLVDB: [장] 높은 퀄리티 / [단] 장면이 적고, timestamp의 ground-truth 부재
[두 가지 데이터셋 예시]

Multi-frame joint conditional generation
- Naive 방식: C-GAN 기반으로 time을 condition으로 넣은 GAN 방법
- 장: 아웃라이어(카메라 모션, 움직이는 물체, 잘못된 프레임)에 강인하게 학습
- 단: 그러나 시간에 독립적인 학습때문에 그럴듯한 비디오가 생성되기 힘듦 (예를 들어 어떤 시각의 illumination은 다른날 다른 시각의 것과 관련이 있을 수 있음)
- 제안하는 방법: 시간 변화에 연속적으로 학습
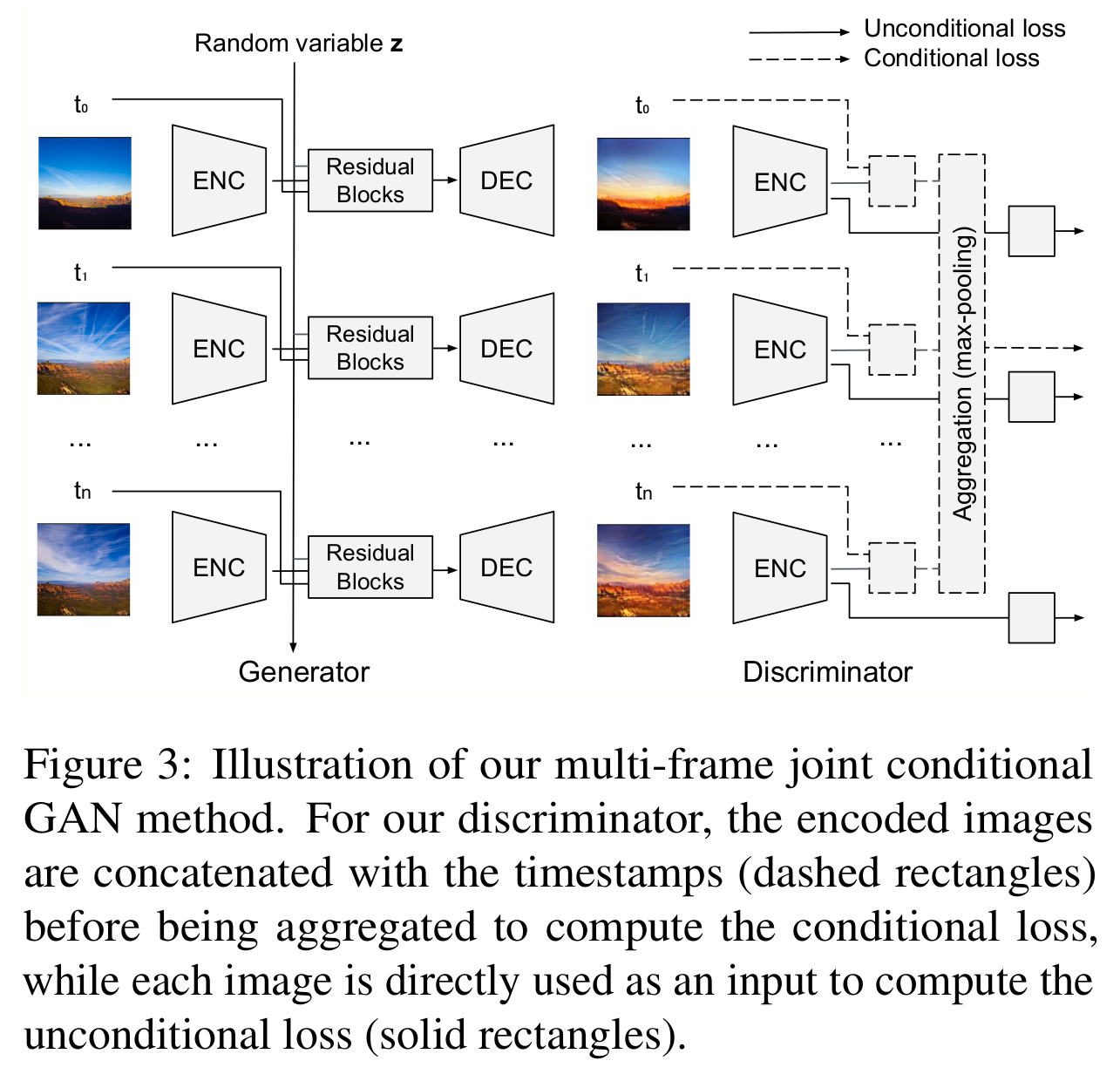
- Generator
- 일반적인 encoder-decoder 구조이며 여러개의 영상과 timestamp를 입력으로 넣음
- Latent variable은 정규 분포로 부터 샘플링하며 모든 시간을 공유하여 temporal 성분을 이어준다.
- Residual block은 를 이어준다.
- Discriminator
- Unconditional discriminator (각 입력 이미지, 각 생성된 이미지): 각 영상별 Real/Fake 판단
- Conditional discriminator (입력 프레임셋, 생성된 프레임셋): 원본 프레임 셋이 진짜 timestamp sequence 인지, 생성된 프레임 셋(복원된 영상들, timestamp)이 가짜인지, mismatched pair 프레임 셋이 가짜인지 판단 (각 복원된 영상이 해당 timestamp에 해당하는지, 시간에 따라 변하는 color tone이 실제같은지 판단, 이 때 max pooling을 사용하며 unorder set의 입력이 가능하고 discriminator score는 permutation-invariant)
[Multi-frame joint conditional GAN 방법]
Semi-supervised learning (multi-domain)
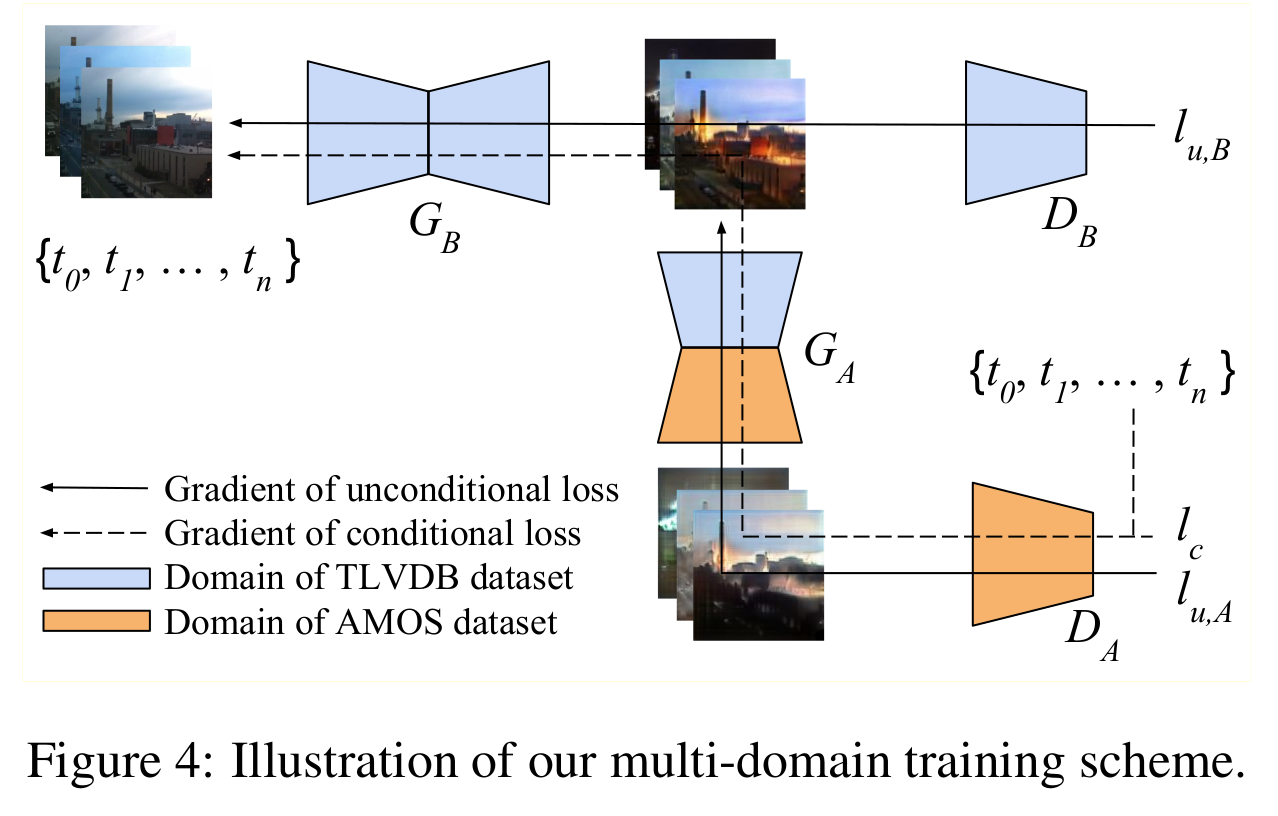
- Naive 방식: 그냥 두 데이터셋을 합쳐서 unconditional image discriminator를 학습한다고 해도 domain discrepancy 때문에 결과가 좋지 않다.
- 제안하는 방법: Image domain translation방식을 기반으로 두 데이터셋의 분포 차이를 효율적으로 다룸
- TLVDB로부터 time-lapse 비디오 합성, AMOS로부터 연속적인 illumination 변화 학습
- 그림에서 화살표 반대로 보는게 편하며, 윗 줄은 time stamp가 없는 TLVDB 데이터셋, 아래 줄은 AMOS 데이터셋
- Timestamp는 AMOS데이터셋에 있는 것을 사용하며, conditional loss는 로 통과되는 흐름에서 사용된다.
- Unconditional loss
- : 원본 영상의 진짜 여부, 에서 생성된 영상의 가짜여부
- : 원본 영상의 진짜 여부, 에서 생성된 영상의 가짜여부
- Conditional loss
- : 원본 프레임 셋의 진짜 여부, 에서 생성된 프레임 셋의 가짜여부, mismatched pair 프레임 셋의 가짜여부
- Reconstruction loss
- 에서 생성된 영상과 에서 생성된 영상이 동일한 timestamp에서 같도록
[Multi-domain training scheme]
Training procedure
- 먼저 업데이트, 업데이트, 업데이트
[Training algorithm]

Guided upsampling
[Guided upsampling (post processing)]

Experimental results
[Time-lapse video 생성 결과]

[Failure cases 생성 결과]

Comments
- 평가가 공정한가에 대한 의문
- 애초에 다른 논문이랑 평가가 다른
- User study를 사용했는데 너무 적은 인원 수 (10명)
References
[1] Nam, Seonghyeon, et al. “End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image.” arXiv preprint arXiv:1904.00680 (2019).