[2018 CVPR] Single View Stereo Matching
Table of content (short-version) [paper] [github]
Summary
- Single view에서 depth를 구하는 방식 (Semi-supervised)
- 메인 아이디어
- View synthesis network: left 이미지를 가지고 right 이미지를 만든다.
- Stereo matching network: 둘의 correlation을 구해 encoder-decoder를 통과하여 depth를 추정한다.
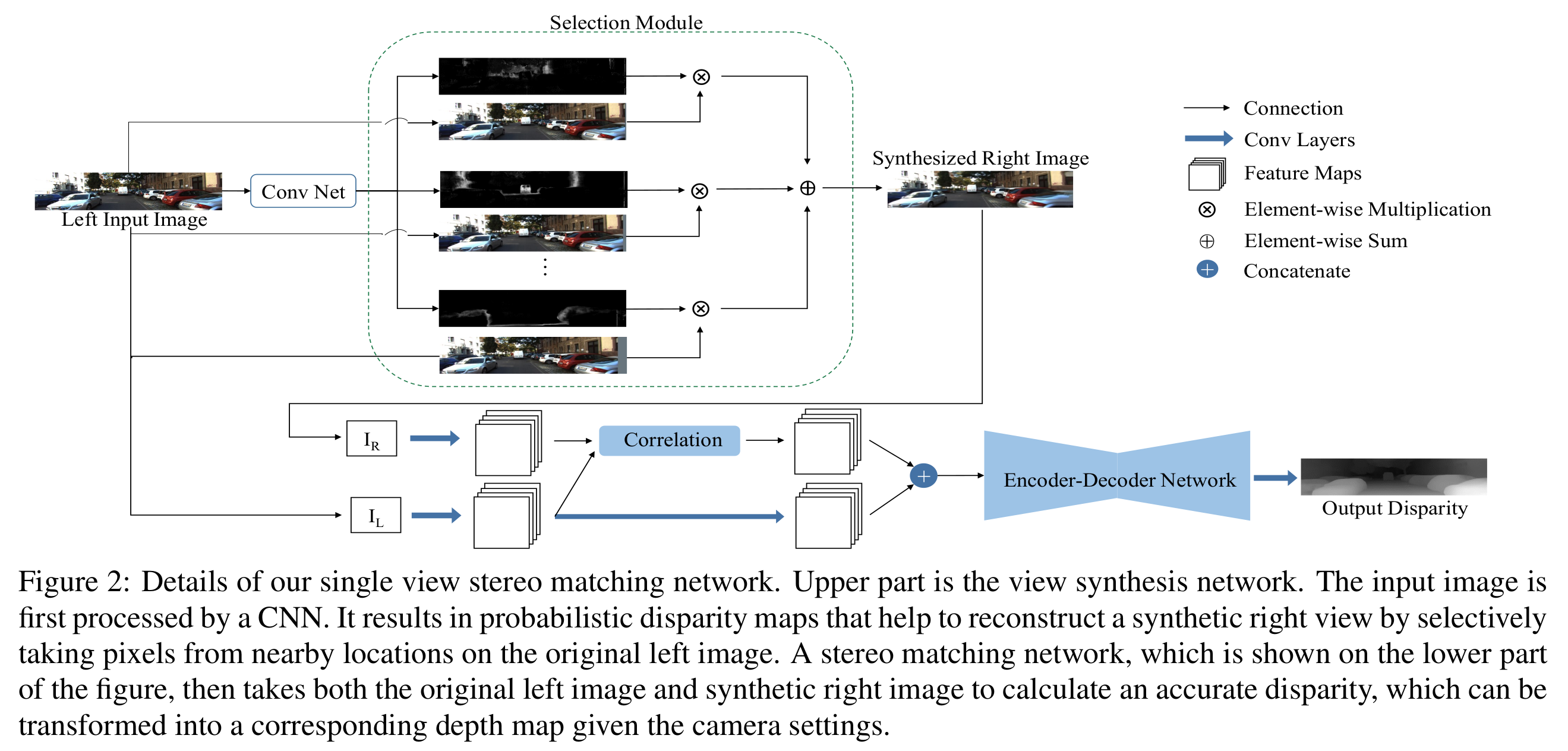
Architecture
View synthesis network
- left 이미지를 가지고 right 이미지를 만든다.
- Deep3D[2] 방식을 기반으로 적용
- 2D image로 3D video를 자동으로 conversion하는 논문
- Probabilistic disparity map을 뽑는다.
Stereo matching network
- 둘의 correlation을 구해 encoder-decoder를 통과하여 depth를 추정한다.
- DispNetC[3] 방식을 기반으로 적용
- 기존의 2D correlation이 아닌 1D correlation을 적용한 방법
- Explicit하게 geometric transformation을 모델링
- Horizontal correlation이 가장 비슷한 부분을 찾는데 효과적
Training
- 각각 학습한 뒤에 joint training (최종 end-to-end)
- 각각의 네트워크는 미세한 아키텍처 차이와 학습 방식이 약간 다름
[전체 프레임워크]
Experimental results
[실험 결과]

Comments
- 두 개 합친 간단한 아이디어인데도 sub-network 두개 나눈 것에 대해서 분석적인 내용이 많아서 spotlight + 높은 성능
- Single view가 아니더라도 이런식으로 합성을 하는 방식은 stereo에서도 한쪽을 이용해서 multi-view로 만드는게 성능 향상에 도움이 될 수 있기에 사용되곤 한다. (data augmentation 느낌)
References
[1] Luo, Yue, et al. “Single view stereo matching.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[2] J. Xie, R. Girshick, and A. Farhadi. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. In ECCV, 2016.
[3] N. Mayer, E. Ilg, P. Häusser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In CVPR, 2016.