[2019 CVPR] Gait Recognition via Disentangled Representation Learning
Table of content (full-version) [paper]
Summary
[요약]
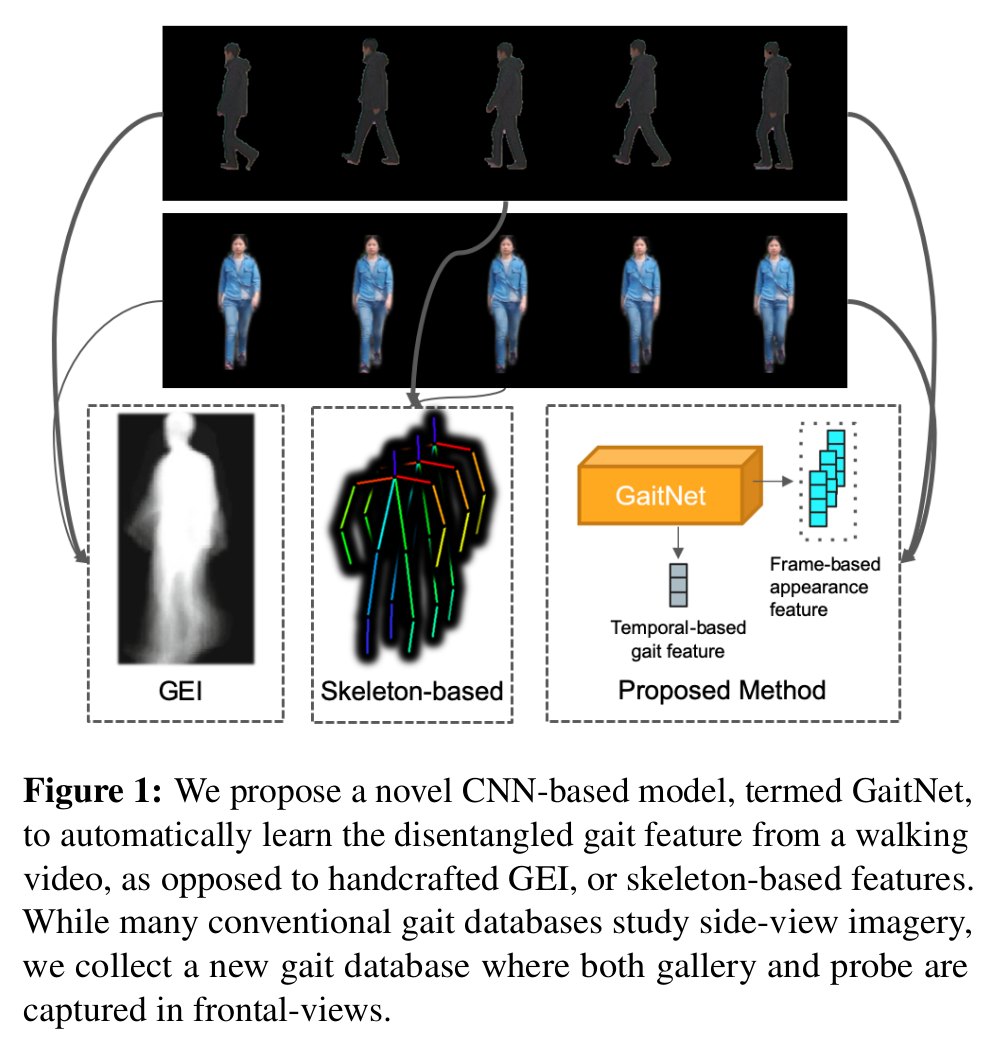
- Cross reconstruction loss(서로 다른 시간의 두 영상이 들어올 때, 첫번째 영상의 appearance feature 두번째 영상의 pose feature를 이용하여 두번째 영상처럼 만드는 방법)와 gait similarity loss(같은사람이지만 다른 condition을 가진 영상들의 pose feature를 서로 유사하게 만드는 방법)를 통해서 appearance/gait feature를 disentangle하고 pose feature를 multi-layer LSTM에 통과시켜 temporal 성분이 포함된 gait feature를 추출한다.
- 고화질의 frontal-view gait DB를 제공한다.
- 논문을 읽기 쉽게 잘썼음
Motivation
- 사람의 걸음걸이에 대한 feature는 외형적 변화(옷, 시점, 짐, 등)에 invariant 해야한다.
- 이런 invariant feature를 추출하기 위한 기존의 방법(GEI나 skeleton)들은 gait 정보가 부족하거나, 불필요한 정보를 생성한다.
- 따라서 사람의 appearance/pose feature를 자동으로 disentangle하는 Gait-Net을 제안한다.
Architecture
[전체 프레임워크]
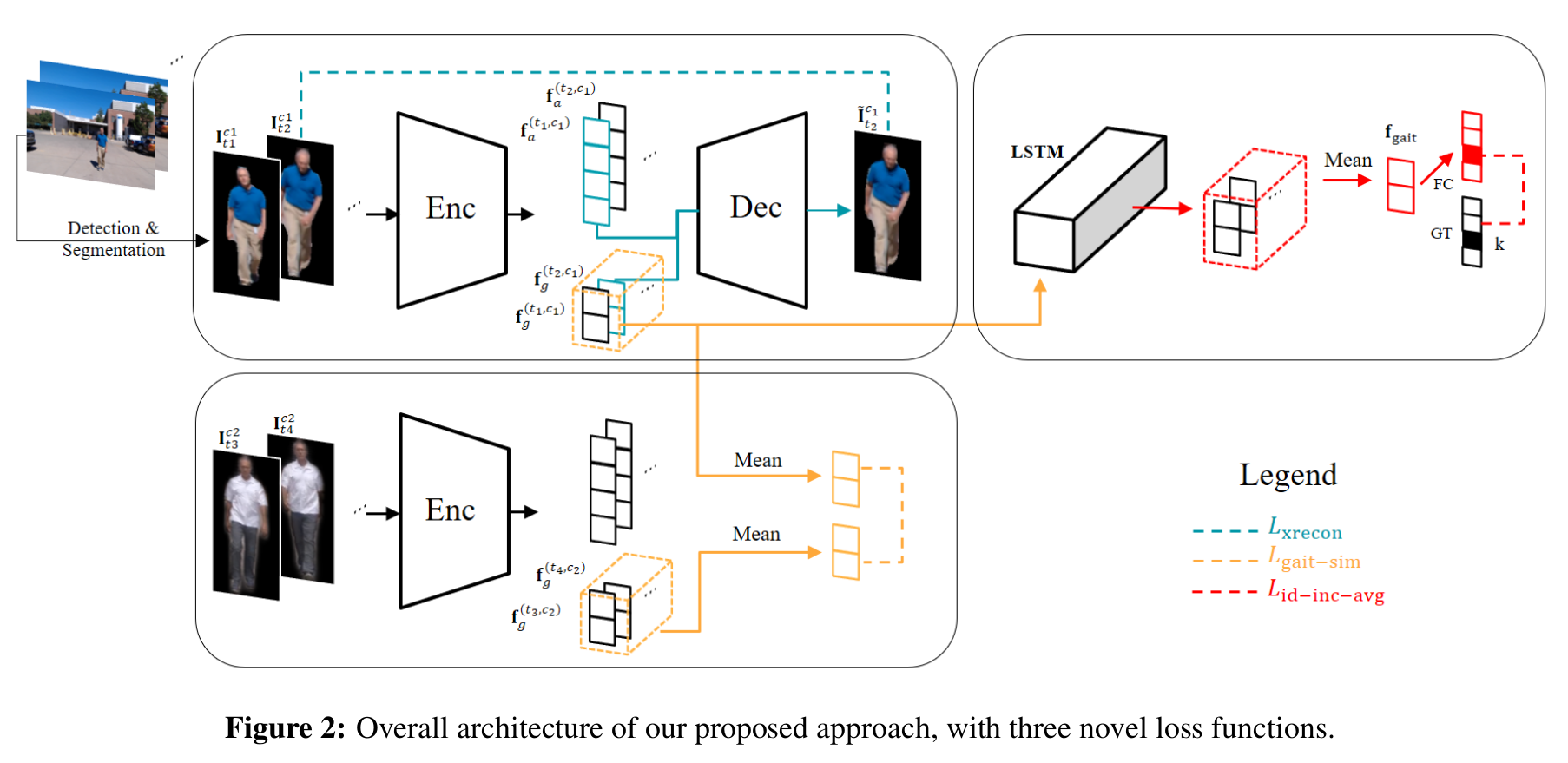
- 기존의 DR-GAN이랑 다른 점
- Adversarial 학습 없이 novel loss function을 디자인 했다는 점
- Pose나 appearance에 관련된 label이 필요없다는 점(label을 이산적으로 정의하기 힘듬, unsupervised)
- 전체 구조
- Appearance/pose feature를 frame-level disentanglement 수행 후 LSTM에 의해 temporal 정보 융합
Apperance/pose feature disentanglement
- Cross reconstruction loss
$$L_{xrecon} = \left \| \mathit{D} (f^{t_1}_a, f^{t_2}_g) - I_{t_2} \right \|^2_2$$
- 서로 다른 시간의 두 영상이 들어올 때, 첫번째 영상의 appearance feature 두번째 영상의 pose feature를 이용하여 두번째 영상처럼 만드는 방법
- Gait similarity loss
$$L_{gait-sim} = \left \| \frac{1}{n_1} \sum^{n_1}_{t=1} f_g^{(t, c_1)} - \frac{1}{n_2} \sum^{n_2}_{t=1} f_g^{(t, c_2)} \right \|^2_2$$
- 같은사람이지만 다른 condition을 가진 영상들의 pose feature를 서로 유사하게 만드는 방법
- Disentanglement를 잘되게 하기 위함
Temporal aggregation
- Incremental identity loss
$$L_{id-inc-avg} = \frac{1}{n} \sum^n_{t=1} - w_t \log(c_k(\frac{1}{t} \sum^t_{s=1} h^s))$$
- 3 layer LSTM를 사용하여 pose feature의 spatial + temporal 정보 모두 이용
- Classification loss를 사용
- LSTM 특성상 마지막 feature에 영향을 많이 받음 를 매 프레임 평균함
- 총 n프레임이 입력되면 매 프레임마다 평균 걸음걸이 특징이 생성되고 이에 의한 classification loss를 구한 뒤 모든 프레임을 합친다.
- 즉, 3개의 영상이 입력되면 (1 프레임에 대한 걸음걸이 특징에 대한 loss) + (1~2 프레임에 대한 평균 걸음걸이 특징에 대한 loss) + (1~3 프레임에 대한 걸음걸이 특징에 대한 loss)
- 로 사용하지만 1일때도 비슷한 성능
- 최종 매칭하는 과정에서는 를 사용한다.
Training
- Raw 영상에서 Mask R-CNN사용해서 instance segmentation수행 (soft mask사용)
- Input size: 32 64
- 서로 다른 32개의 클립(?)으로부터 한 batch의 비디오 프레임들을 적용한다.
- 20 프레임 비디오에서 random crop하여 사용
Experimental results
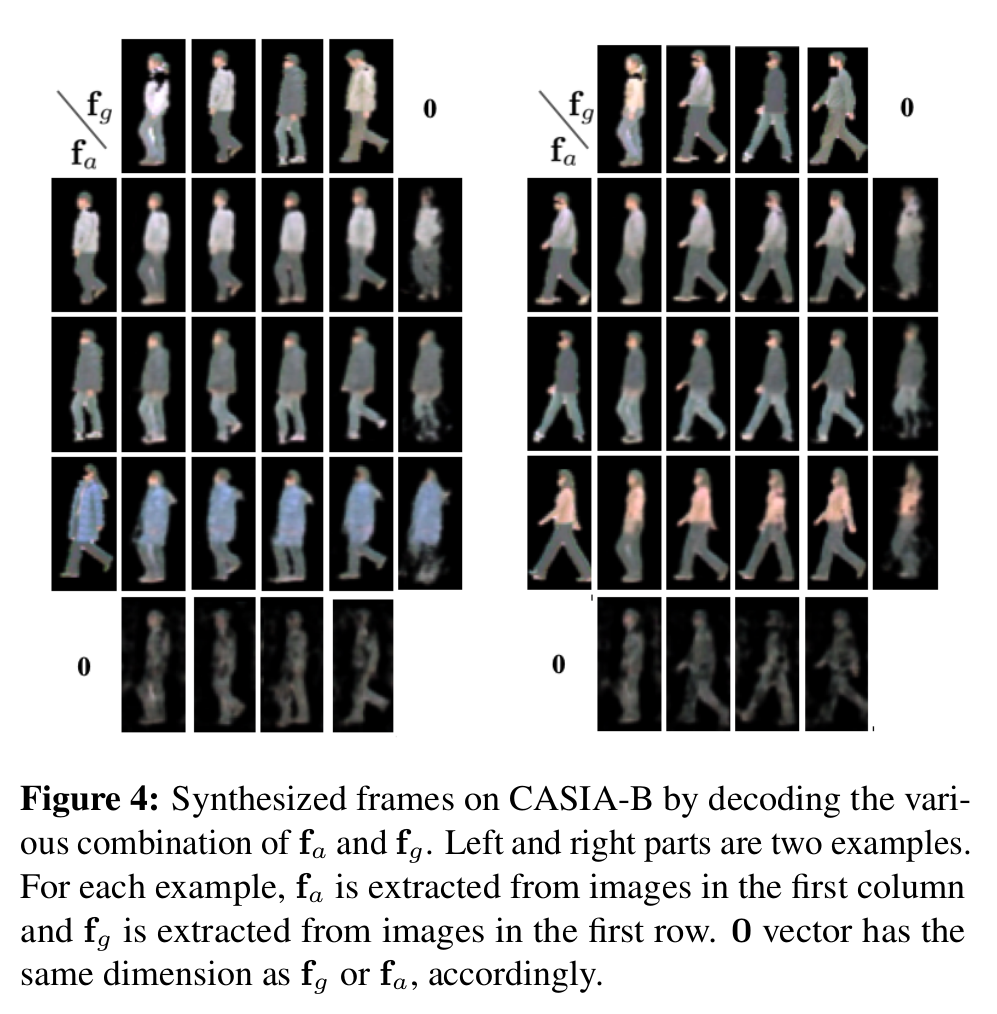
[서로 다른 사람에 대한 pose/appearance를 입력으로 넣을 때 합성된 결과]
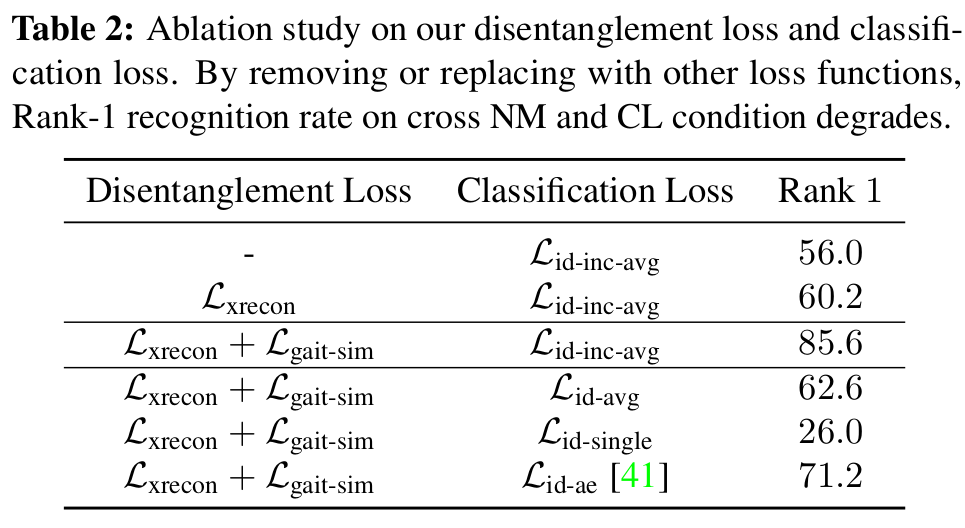
[Loss에 대한 ablation study]
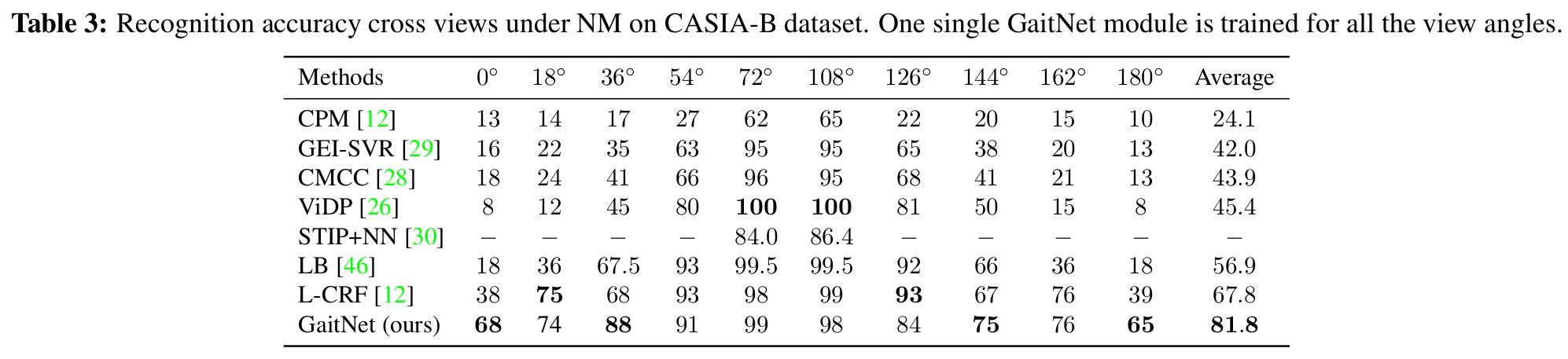
[Recognition accuracy (different views)]
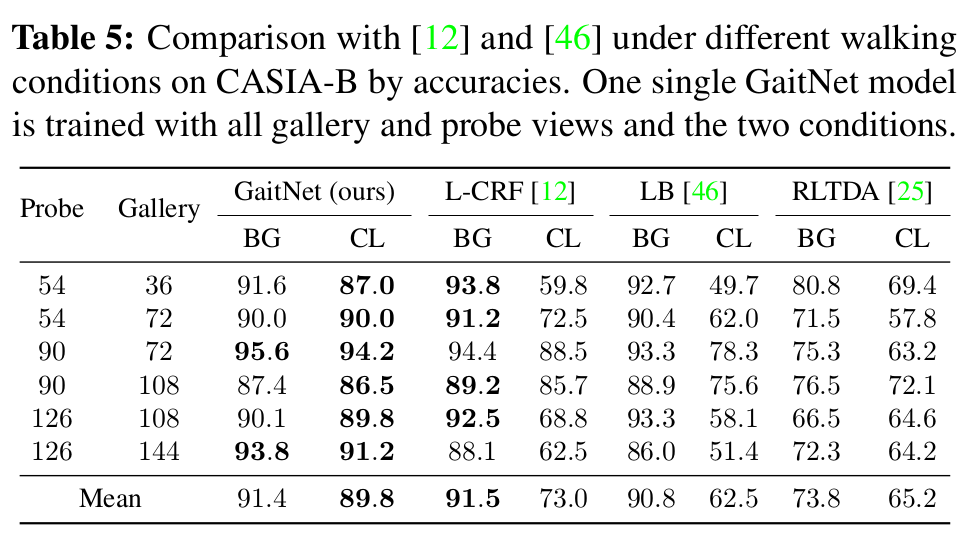
[Recognition accuracy (BG:bag, CL: coat)]
Comment
- Adversarial training 없이 적당한 loss 설계로 disentanglement 했다는 것이 감명깊음
References
[1] Zhang, Ziyuan, et al. “Gait Recognition via Disentangled Representation Learning.” arXiv preprint arXiv:1904.04925 (2019).