[2019 CVPR] Long-Term Feature Banks for Detailed Video Understanding
Table of content (short-version) [paper] [github]
Summary
- long-term으로 action을 인식해야한다는 점 강조
- 기존의 메모리 문제가 있어서 못했던 것을 long-term feature bank라는 것을 도입해서 해결
Motivation
- 기존에는 짧은 clip을 입력으로 하여 3D CNN을 통해 행동을 인식했는데 보다 더 킨 클립이 필요하다.
- 그래서 short-term feature와 long-term feature를 뽑아 융합하겠다.
- 융합은 feature back operator에 의해서 수행
[Long-term context의 필요성 1]

[Long-term context의 필요성 2]

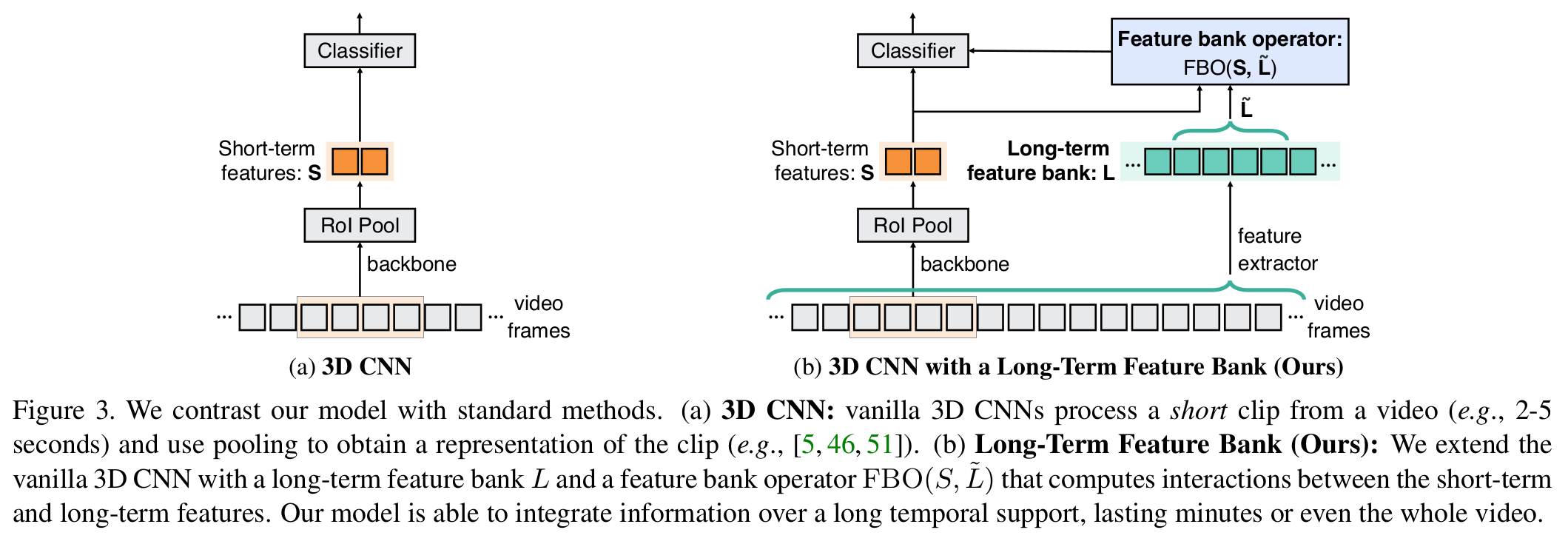
Architecture
- 전체 프레임워크
- 기존에 방식과 다르게 long-term 정보를 같이 융합하여 행동인식
[전체 프레임워크]
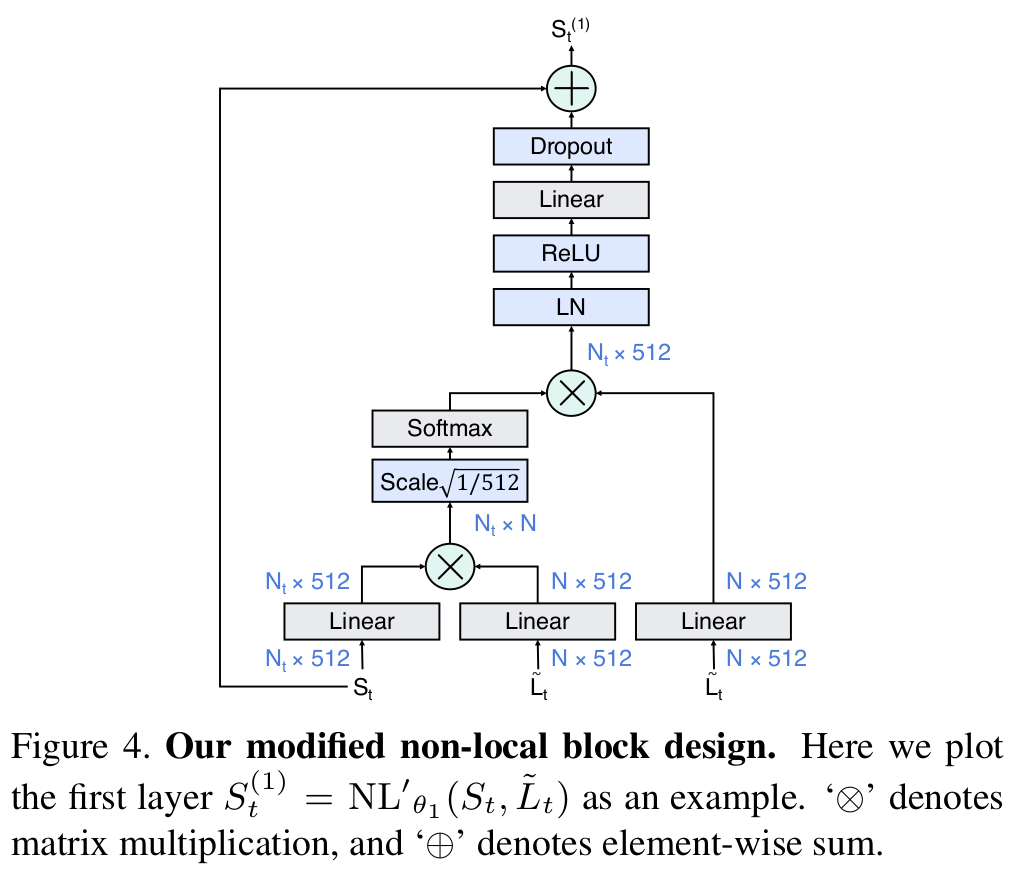
- Modified non-local block
- 기존에 방식과 다른점은 short-term정보만 넣은거에 비해, 입력으로 long-term 정보까지 넣어서 융합한다는 것
- 즉, short-term 정보와 long-term정보가 non-local 연산(융합)되었다는 것으로 볼 수 있다.
[수정된 non-local block]
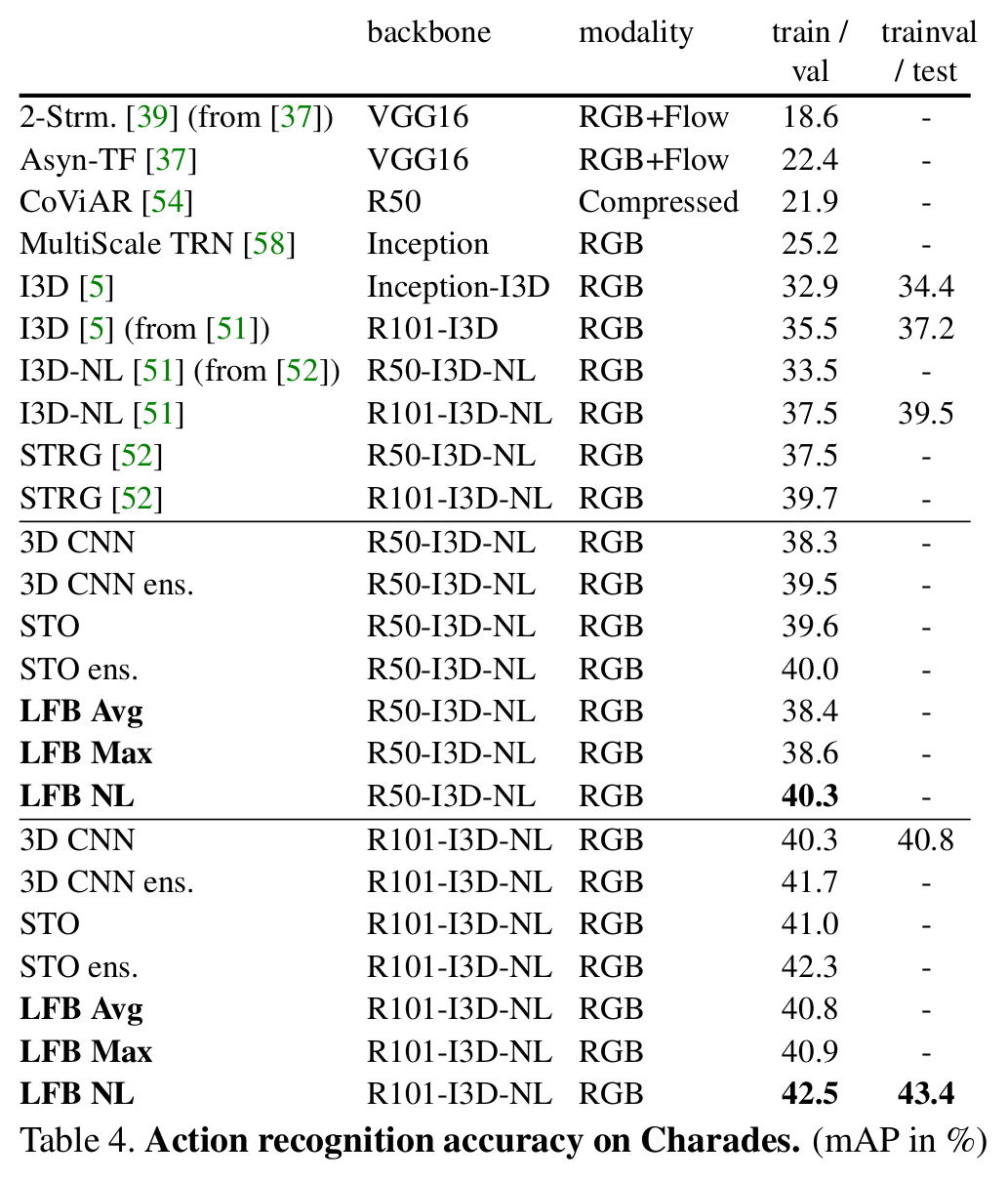
Experimental results
- 영상 길이 ablation
- 맞는 결과(파란색)는 long-term으로 볼수록 예측 성능이 높아짐
- 틀린 결과(빨간색)는 long-term으로 볼수록 예측 성능이 감소
[영상 길이에 따른 예측결과 비교예시]

- 인식 성능 (기존 방법보다 높은 성능)
[실험 결과(action recognition 성능)]
Comments
tracking에서도 적용할 수 있지 않을까?
References
[1] Wu, Chao-Yuan, et al. “Long-Term Feature Banks for Detailed Video Understanding.” arXiv preprint arXiv:1812.05038 (2018).