[2015 NIPS] Deep Convolutional Inverse Graphics Network
Table of content (short-version) [paper] [github]
Summary
- 영상의 표현을 해석가능하게 만들어 원하는 영상 생성 가능
- Disentanglement 논문의 초기 버전
- 한계점: 원하는 variation만을 갖는 데이터셋을 얻기가 힘들다.
Architecture
[전체 프레임워크]
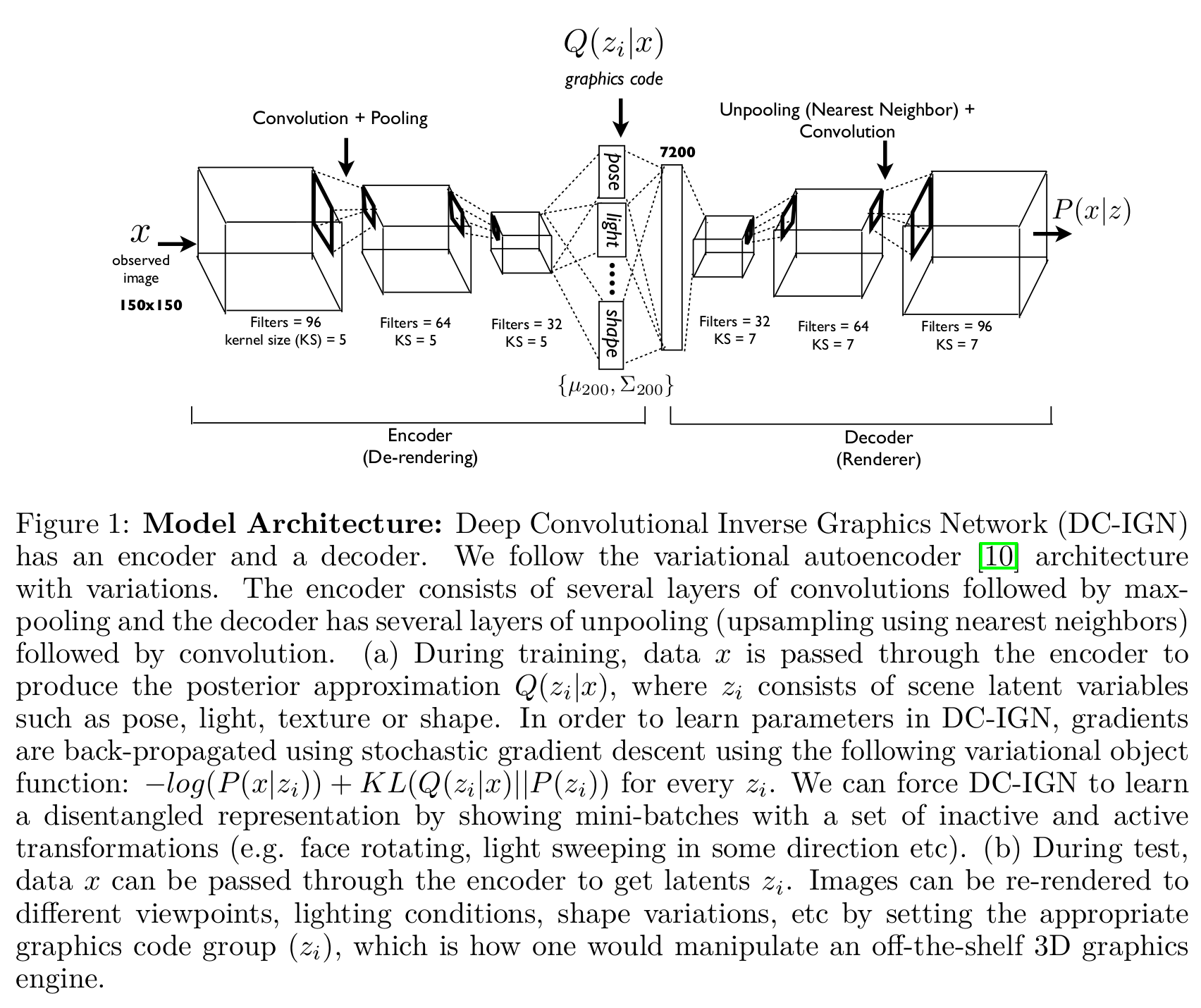
[latent vector의 구조]

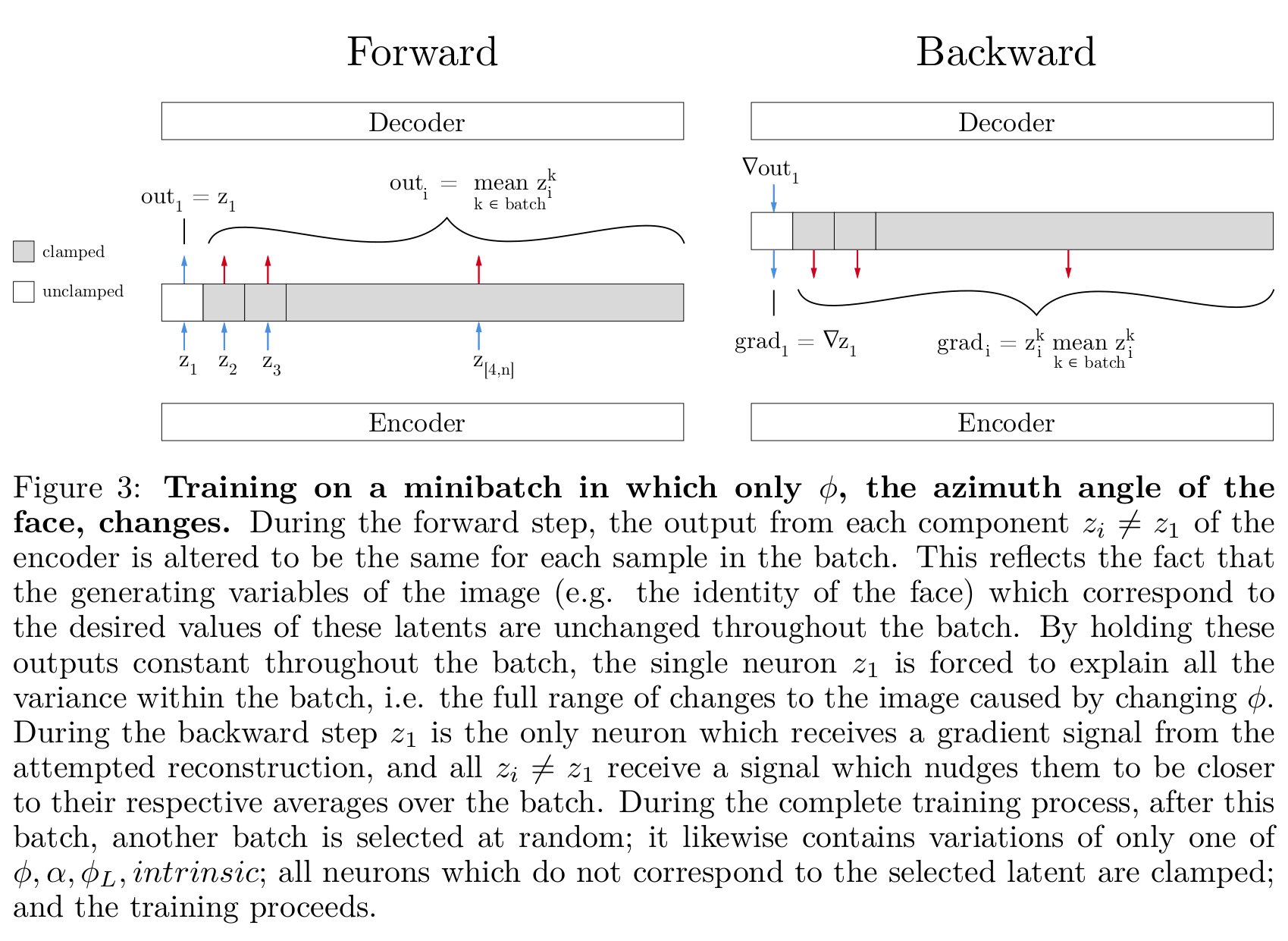
- 학습 방법
- 학습하려는 특성에 대응하는 은 제대로 forward, backward하고 나머지 z는 clamp하여 z의 배치 평균을 이용한다.
[학습 방법]
Experimental results
[실험결과: light direction & pose elevation 변화]

[실험결과: pose azimuth 변화]

References
[1] Kulkarni, Tejas D., et al. “Deep convolutional inverse graphics network.” Advances in neural information processing systems. 2015.
[2] https://lyusungwon.github.io/generative-models/2018/05/01/dcign.html