[2015 NIPS] CVAE, Learning Structured Output Representation using Deep Conditional Generative Models
Table of content (short-version) [paper] [github]
Summary
- 레이블 정보를 알 때 VAE를 학습하는 방법.
- ELBO 식은 conditional probability만 조금 다르고 동일.
- 기존의 VAE는 x에서 직접적으로 z를 출력하고 z에서 직접적으로 x를 생성하기에 특정 데이터 생성 불가
- 레이블을 유지한 채 z(스타일)을 바꾸면 MNIST인 경우 회전되거나 두께가 변한다.
Architecture
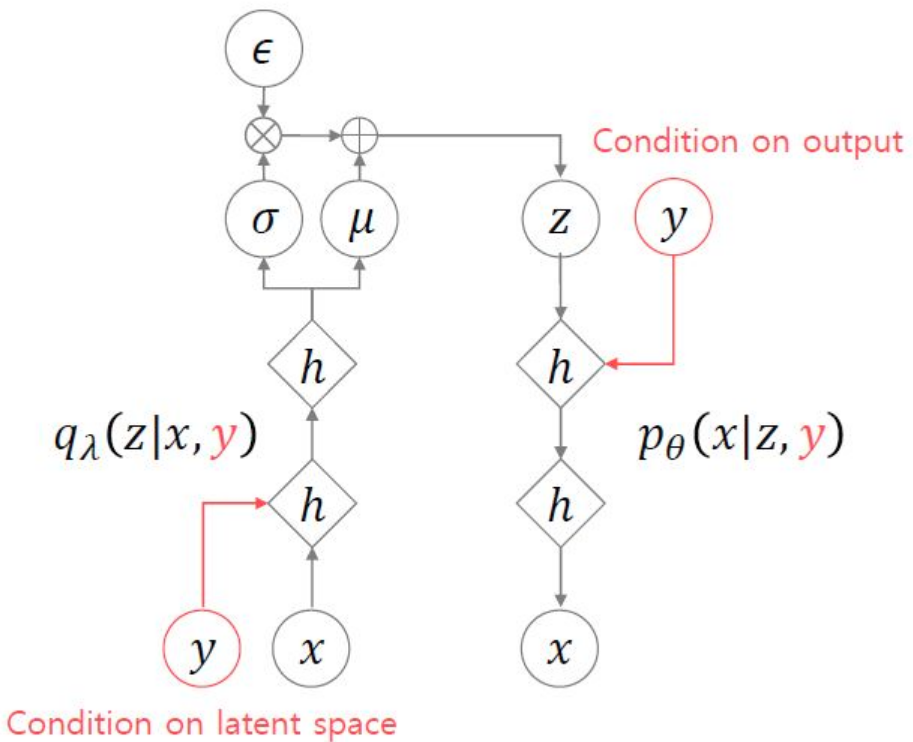
[기본 VAE에서 conditional 추가된 버전 (Supervised)]
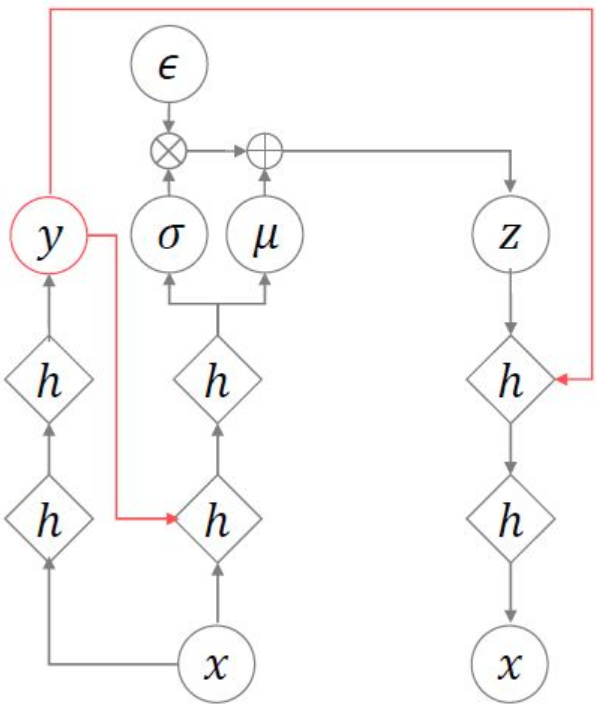
[알고있는 레이블과 모르고 있는 레이블이 있을 때, 추가적인 인코더를 이용하여 모르는 label을 추정하고 나머지 알고있는 label은 y 그대로 입력 (Semi-supervised)]
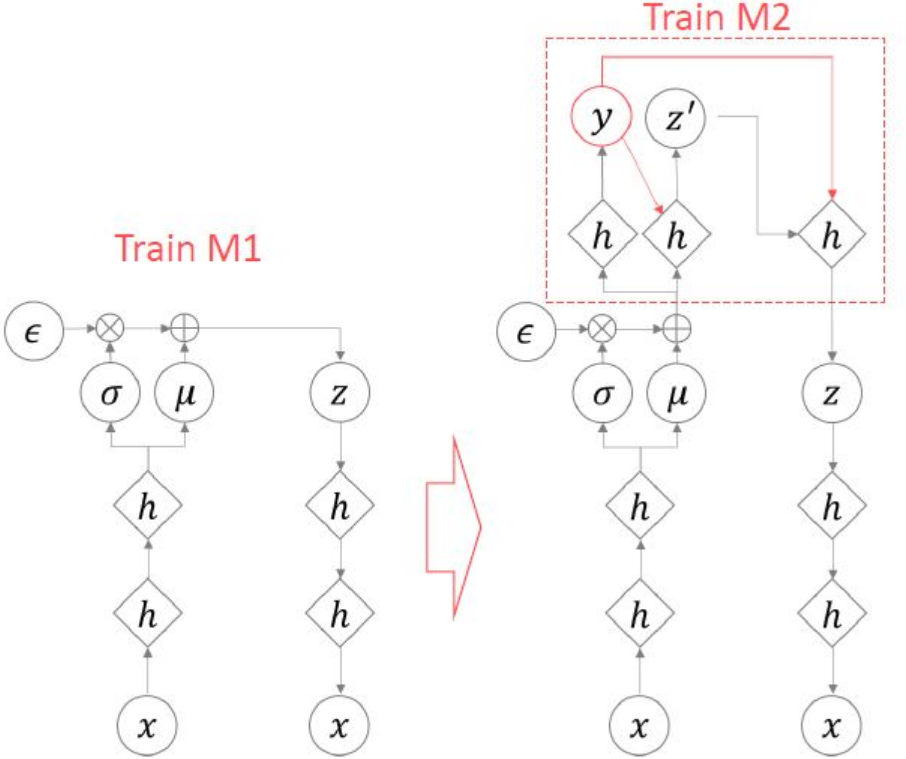
[기본 VAE를 학습한 이유에 추가적인 인코더 디코더로 레이블 추가 학습]
References
[1] Sohn, Kihyuk, Honglak Lee, and Xinchen Yan. “Learning structured output representation using deep conditional generative models.” Advances in neural information processing systems. 2015.
[2] https://wiseodd.github.io/techblog/2016/12/17/conditional-vae/
[3] https://ratsgo.github.io/generative%20model/2018/01/28/VAEs/
[4] https://blog.naver.com/stykworld/221377790514