[2019 CVPR] Re-Identification Supervised Texture Generation
Table of content (full-version) [paper]
Summary
- Re-identification의 supervision 하에 사람의 텍스쳐를 3D 형태로 생성하는 end-to-end network
- Re-identification network는 perceptual metrics로써 사용
Motivation
- Single image에서 textured 3D model을 생성하는 것은 challenging issue (occlusion and background texture 문제)
- 이 문제들을 해결하기 위해서 re-identification의 supervision을 이용
- Re-identification에서는 다른 시점에서도 texture를 보고 알아맞춤 occlusion 문제 해결가능
- Re-identification에서는 background clutter에 상관 없이 사람에 대한 특징을 잘 추출함 background texture 문제 해결가능
Architecture
[전체 프레임워크]
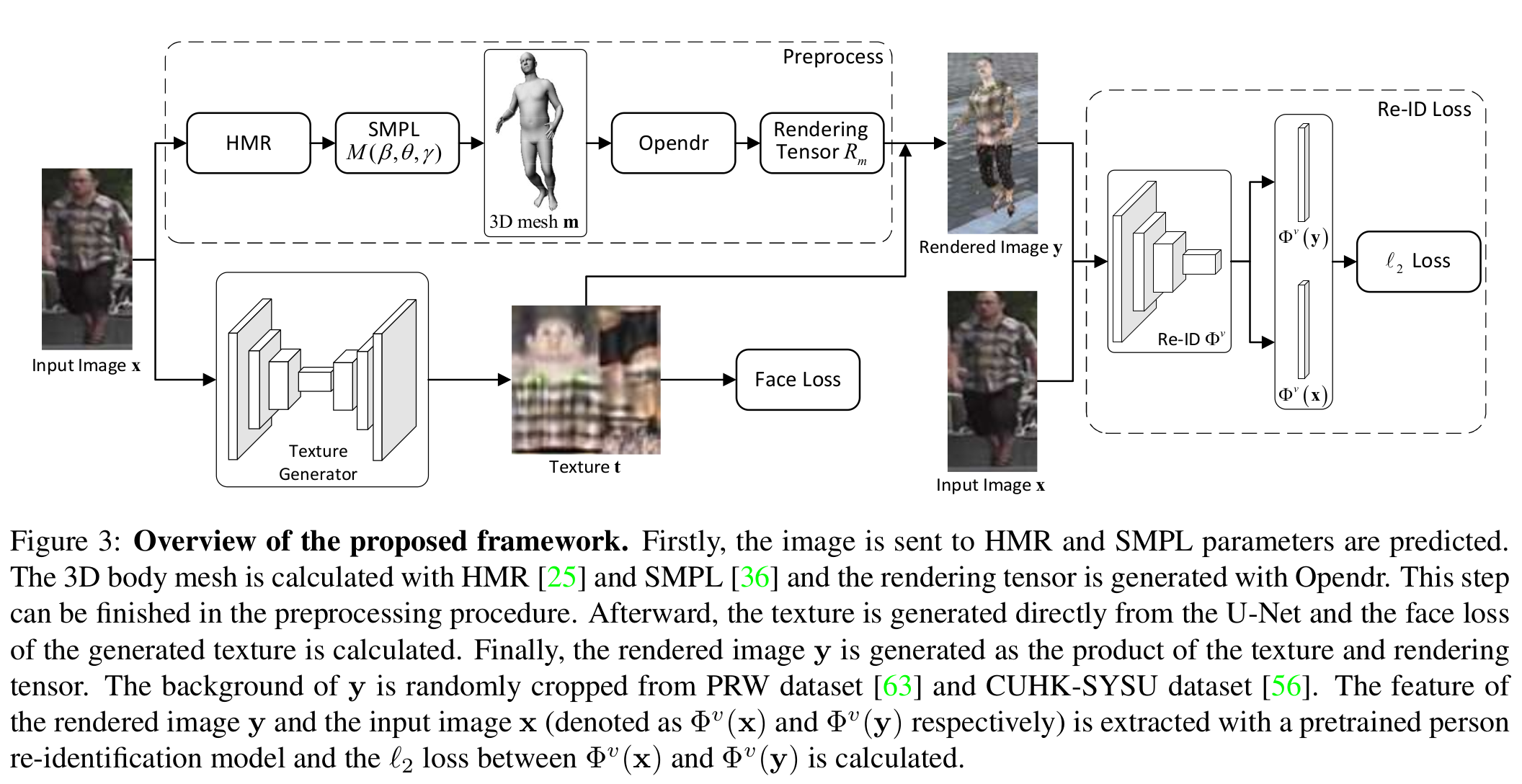
- 따로 GAN-style discriminator와 loss를 결합하지 않는 이유는 rendered 이미지와 실제 이미지와 명확한 스타일 gap이 있기 때문이다. (D가 real/fake 구분하기 너무 쉬움)
- HMR[2]: 3d body pose and shape estimation (iterative 3D regression module) shape 10dim, pose 72dim, translation 3dim, K=23joints
- SMPL[3]: shape, pose, translation parameters 3차원의 N=6890 vertices로 삼각형의 몸통 mesh 형성 (미분가능)
- Opendr[4]: differentiable renderer, pre-processing
- Re-ID loss: rendered image 와 input image 가 pre-trained re-id network(PCB[5] 사용)를 통과하면서 1~4번째까지의 feature activation에 대한 L2 차이를 이용한다. 즉, low, mid, high-level feature statistics 비교하는 것이다. 같은 사람일 경우 해당 loss를 최소화하며, 다른 사람이면 최대화한다.
- Face loss: 얼굴과 팔부분에 대해서 U-Net에 의해서 생성된 텍스처와 SURREAL[6]로 부터 3D scanning된 텍스처 사이의 L1 loss.
Experimental results
- Dataset: Market-1501
- Metric: SSIM, Mask-SSIM
- Face loss ablation
- Pasted face: 바로 SURREAL에서 추출한 텍스처를 쓰지 않는 이유는 머리와 몸통 사이의 색 대조를 맞추기 위함이다.
[Face loss에 대한 ablation studies]

- Re-ID loss ablation 1
- Perceptual loss: ImageNet 통과한 것이며 바디 텍스쳐만을 보기 보다는 전반적인 텍스쳐를 맞추는 경향이 있어서 안 좋다.
- Pixelwise-L1 loss: HMR과정에 의존적이라서 체형이 맞지 않으면 안좋다.
[Re-ID loss에 대한 ablation studies 1]

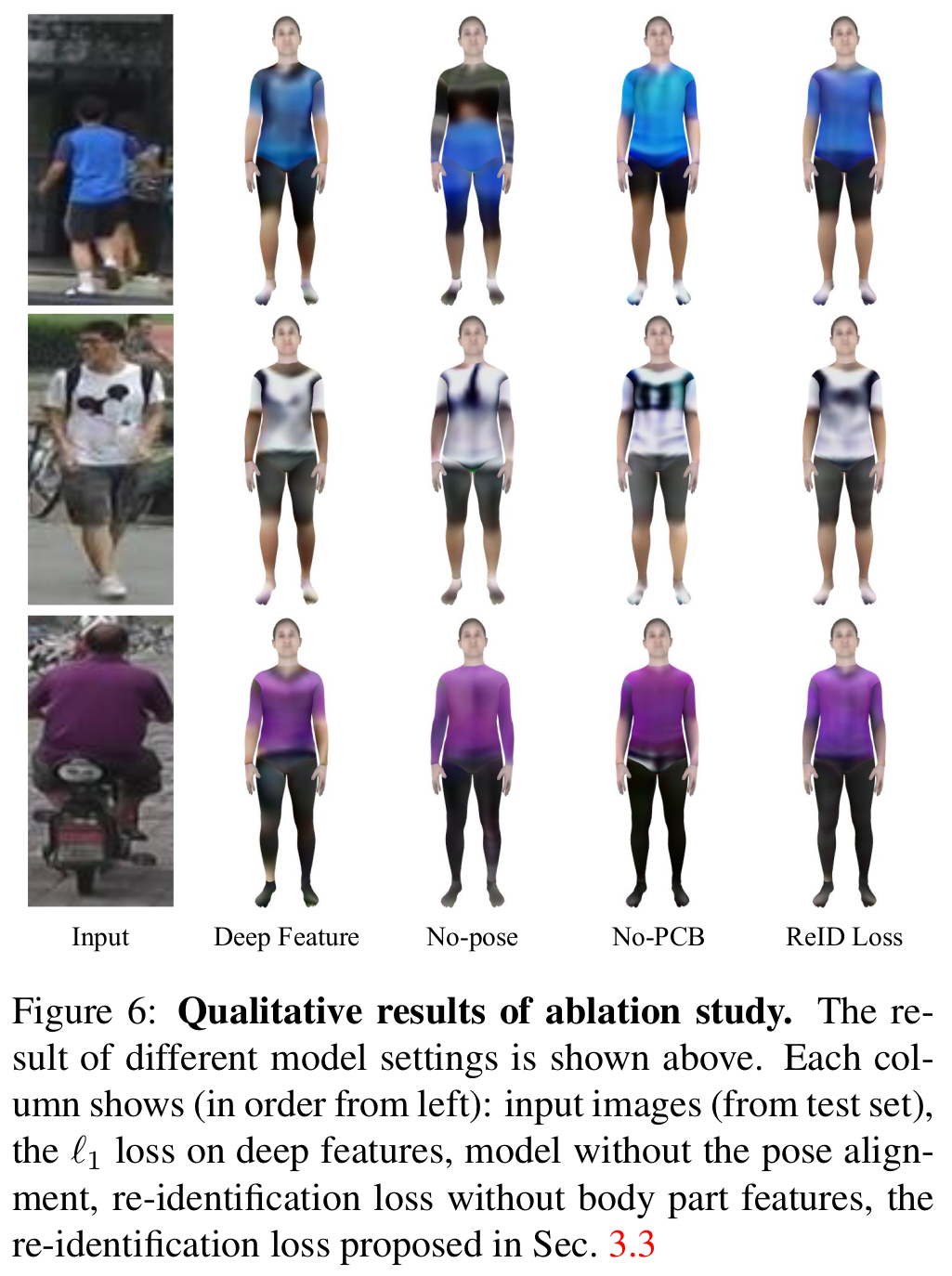
- Re-ID loss ablation 2
- Deep features: re-id network의 마지막 특징벡터의 L1 loss 사용. deep feature만으로는 상세한 텍스처를 표현하기 힘들다는 한계점.
- No-pose: HMR, SMPL과정 없이 re-id network만 믿고 re-id loss 적용. 맨 위 예시에서 사람이 영상 전체에 fit하지 않기에 백그라운드가 상의에 표현됨.
- No-PCB: PCB는 body feature를 구분하여 사용했지만, 구분없이 사용. 팔다리 옷 디테일이 아쉽다.
[Re-ID loss에 대한 ablation studies 2]
Comments
- 따로 HMR이나 SMPL는 학습을 하지 않는 것으로 보이는데 여기에서 극복할 수 없는 한계가 보이는듯. (포즈가 다르면..?)
- 동일한 사람은 pose나 translation을 다르더라도 같은 shape을 주는 방향으로 HMR이랑 SMPL에서 id loss를 줘서 학습할 수는 없나? 3d person re-identification을 할 수는 없을까?
- U-Net에서 가져오는 텍스처 표현도 아쉽다. 즉, 텍스처가 입혀진 렌더링 이미지의 퀄리티가 좋아보이지 않는다. (그 이유는 논문에서 나와있는데, Market-1501자체가 레졸루션이 낮다는 것과, opendr에서 입력되는 텍스처의 크기가 작다는 것이다.)
References
[1] Wang, Jian, et al. “Re-Identification Supervised Texture Generation.” arXiv preprint arXiv:1904.03385 (2019).
[2] Kanazawa, Angjoo, et al. “End-to-end recovery of human shape and pose.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[3] Loper, Matthew, et al. “SMPL: A skinned multi-person linear model.” ACM transactions on graphics (TOG) 34.6 (2015): 248.
[4] Loper, Matthew M., and Michael J. Black. “OpenDR: An approximate differentiable renderer.” European Conference on Computer Vision. Springer, Cham, 2014.
[5] Sun, Yifan, et al. “Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline).” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[6] Varol, Gul, et al. “Learning from synthetic humans.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.