[2019 CVPR] Progressive Pose Attention Transfer for Person Image Generation
Table of content (full-version) [paper] [github]
Summary
- 사람 영상이 주어졌을 때, 주어진 포즈로 변형하기 위한 GAN 네트워크 제안
- Pose-Attentional Transfer Blocks (PATBs)를 여러개 이어서 포즈를 점진적으로 변형
- Better appearance consistency and shape consistency
- Re-identification 분야에서 데이터의 불충분 문제를 완화하기 위해 데이터셋을 확보하는 차원에서 유용하게 사용가능
- 논문을 읽기 쉽게 잘썼음
Motivation
- 어떤 사람의 모든 가능한 포즈나 뷰 영상은 하나의 manifold를 형성한다는 관점에서, 포즈가 크게 변하는 것은 manifold 상에서 이동하기 어렵지만 작은 변화는 local 수준으로 간단화할 수 있을 것이라는 가정으로 점진적인 방법을 고안
- Manifold 위에서 지역적인 이동을 하게끔 PATBs 설계
Architecture
[Notation]
| Symbol | Mean |
|---|---|
| condition image | |
| target image | |
| generated image | |
| condition pose | |
| target pose |
[전체 프레임워크]
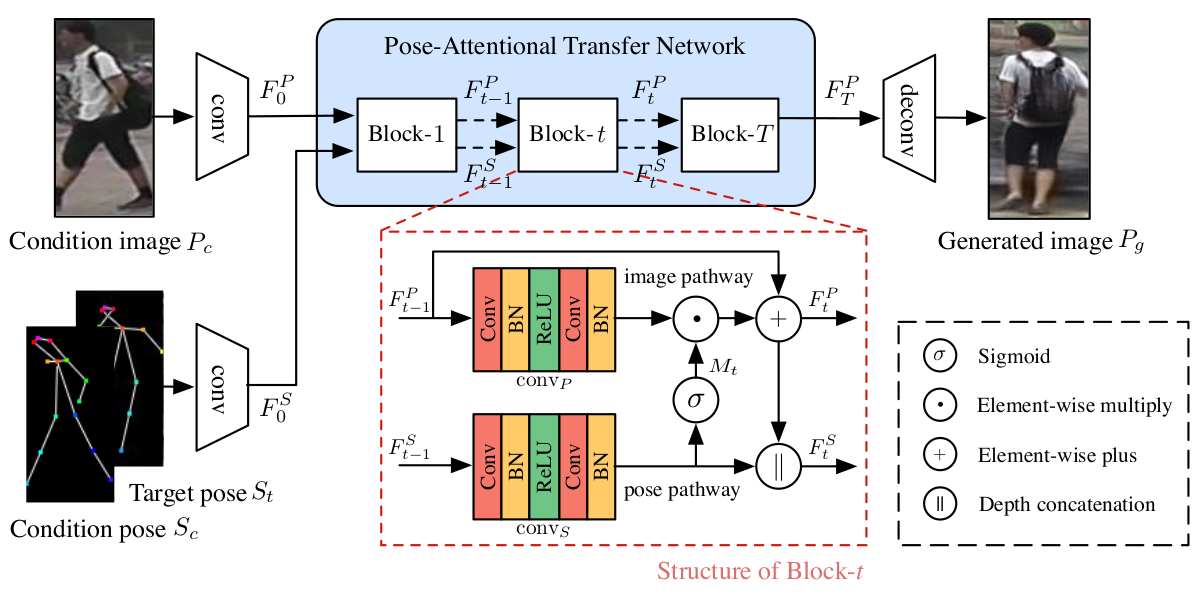
Generator
- Encoder
- 첫 번째 입력으로 condition (source) 이미지가 (N=2) down-sampling conv layer에 통과 ()
- 두 번째 입력으로 condition pose (18 channel heat map) 이미지가 같은 형식의 target pose와 depth 축으로 합쳐져서 N down-sampling conv layer에 통과 () [encoder이후에 concat하는 것보다 계산복잡도 적다는 장점]
- Pose-Attentional Transfer Network
- 큰 틀
- 동일한 구조의 PATB들이 cascade 형식으로 구성
- 이미지 특징벡터와 와 포즈 특징벡터 가 입력되고 포즈는 버려진 채 최종 변형된 이미지 특징벡터 만 출력
- 하나의 PATB는 image pathway와 pose pathway로 구성되며 둘은 상호작용
- Pose Attention Masks
- condition pose는 어디에서 condition patch를 샘플할지, target pose는 target patch를 어디로 놓을지 가이드한다.
- 이러한 힌트는 0~1사이의 attention mask 에 의해서 실현된다.
- Image Code Update
- 포즈에서 얻어진 에 의해서 번째 이미지 특징은 변형되고 또한 residual connection에 의해 일부는 보존되어 최종적으로 번째 이미지 특징이 업데이트된다. [여러개의 PATB가 있음에도 불구하고 residual connection에 의해서 학습이 쉽게 되는 것이다.]
- Pose Code Update
- 이미지 코드를 다음 블락에서도 점진적으로 변화시키기 위해서 이미지 코드가 업데이트 된 것에 맞춰 포즈 코드가 업데이트 되어야 한다.
- 포즈 코드는 에 의해서 뎁스가 작아지게 하고 이미지 코드를 depthwise concat하여 크기를 복원한다.
- 큰 틀
- Decoder
- N deconvolution layer에 의해서 최종 출력 이미지 생성
Discriminator
- 동일한 구조의 두 discriminator 이용 (appearance discriminator and shape discriminator )
- 는 (입력 이미지 )와 (생성된 이미지 or 타겟 이미지 )를 depth축으로 concat하여 입력을 받으며 CNN구조와 최종으로 softmax layer를 거쳐 라는 appearance consistency score를 출력한다. (생성된 이미지는 점수 낮게, 타겟 이미지면 점수 높게)
- 는 (타겟 포즈 )와 (생성된 이미지 or 타겟 이미지 )를 이용하며, 동일한 구조를 거쳐 라는 shape consistency score를 출력한다. (생성된 이미지는 점수 낮게, 타겟 이미지면 점수 높게)
- 학습 과정에서 Discriminator의 capacity를 향상하기 위하여 2번의 down-sampling convolution 이후에 3번의 residual block을 거친다.
Training
- 최종 loss function은 adversarial loss와 combined L1 loss로 구성된다.
- Adversarial loss는 discriminator가 real/fake를 잘 구분하게 만들기 위한 것으로 discriminator 와 에 의한 loss이다.
- 생성한 영상 을 넣었을 때에는 fake(0)으로 판단하도록 / 타겟 영상 를 넣었을 때에는 real(1)로 판단하도록
- Combined L1 loss는 generator가 생성한 영상 이 타겟 영상 과 최대한 비슷하게 만들기 위한 것으로 일반적인 pixelwise L1 loss와 Perceptual L1 loss를 사용한다. [포즈 distortion을 감소하고 이미지를 보다 자연스럽게 만들기 위해]
- Perceptual L1 loss: Pretrained VGG-19 모델 conv1_2에서 출력된 특징을 비교
- Adversarial loss는 discriminator가 real/fake를 잘 구분하게 만들기 위한 것으로 discriminator 와 에 의한 loss이다.
- GAN의 트레이닝 구조를 따른다 (G / D 따로 학습하며 필요한 소스들이 다르다)
- DeepFashion에서는 Instance normalization / Market-1501에서는 Batch normalization사용
Experimental results
- Dataset: DeepFashion(256x256), Market-1501(128x64)
- Pose joint detector: HPE[2]
- 총 9개의 PATB 사용
- Metrics: SSIM, IS, mask-SSIM, mask-IS, DS등을 사용하지만 부적합, PCKh 제안 (shape consistency를 위해서 사람의 pose joint가 얼마나 정렬되어 있는지 판단) 다른 방법들에 비해서 나은 성능을 보임 (Metric + user study)
-
속도: 60fps
- 포즈 변형 실험 결과
- 포즈는 테스트에 있는 것인데도 불구하고 잘 변형되는 것을 보인다. (Deep fashion이 해상도가 높아서 더 잘된다.)
[Deep fashion 포즈 변형 결과]

[Market-1501 포즈 변형 결과]

- Attention mask 시각화
- Attention mask가 처음에는 몸통, 디테일한 포즈를 잡더니 마지막에는 배경을 잡아서 변화시킨다.
[PATB의 진행정도에 따른 attention mask 모양 변화]

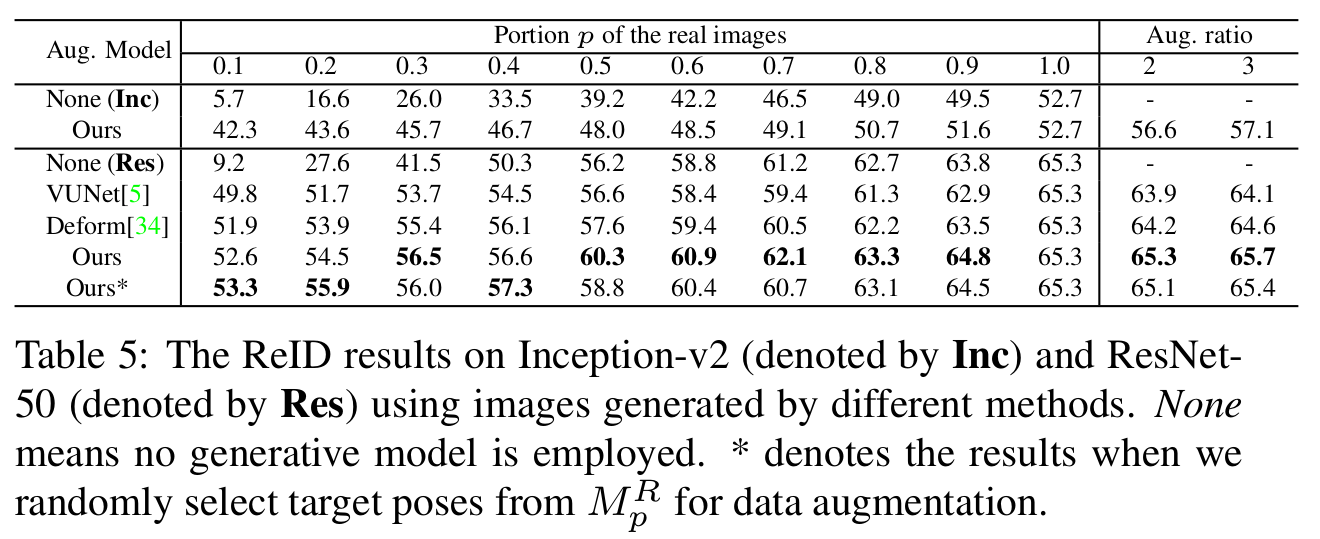
- Re-identification 분야에서의 적용
- Market-1501에서의 data augmentation
- Backbone: ResNet-50 and Inception-v2
- 기존의 training set에서 id의 수는 유지한채 영상 개수 비율을 감소시키고 생성된 데이터로 채워 넣는 방식
[Re-identification 적용 성능]
Comments
- 포즈는 그렇다 쳐도 얼굴도 realistic 변화가 오는게 신기하다.
- 시각적 차이가 있는것 치고는 수치 차이가 없다.
- PATB의 개수에서 trade-off (성능과 효율성)가 있다고 하여 adaptive하게 가능할 것으로 보인다.
- Re-identification 분야로의 적용에서 아쉬운게, 기존 트레이닝 셋을 유지한 채 data augmentation을 통해 성능을 더 부스팅하는 것(표의 오른쪽)이 더 큰 목적이지 않나 생각이 드는데 성능 향상이 미미하고 또한 image classification을 위한 backbone network가 아닌 최신 re-id 기술을 차용하여 (적어도 IDE 정도는) 적용했어야 하지 않나 싶음
- 학습을 위해서는 같은 사람의 다른 포즈 영상 이 있어야 한다. 테스트 때는 가 필요없기 때문에 임의의 포즈도 상관없다.
References
[1] Zhu, Zhen, et al. “Progressive Pose Attention Transfer for Person Image Generation.” arXiv preprint arXiv:1904.03349 (2019).
[2] Cao, Zhe, et al. “Realtime multi-person 2d pose estimation using part affinity fields.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.