[2018 AAAI] Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Table of content (full-version) [paper] [github]
Summary
- Skeleton-based action recognition 논문 (포즈 추정 정보만 이용하여 행동을 이식하는 분야)
- Spatial-Temporal Graph Convolutional Networks (ST-GCN) 제안
- 노드: body joints, feature vector (coordinate vectors + estimation confidence)
- 엣지: spatial(intra-body edges, neighbor node <= 1), temporal(inter-frame edges, temporal kernel size = 9)
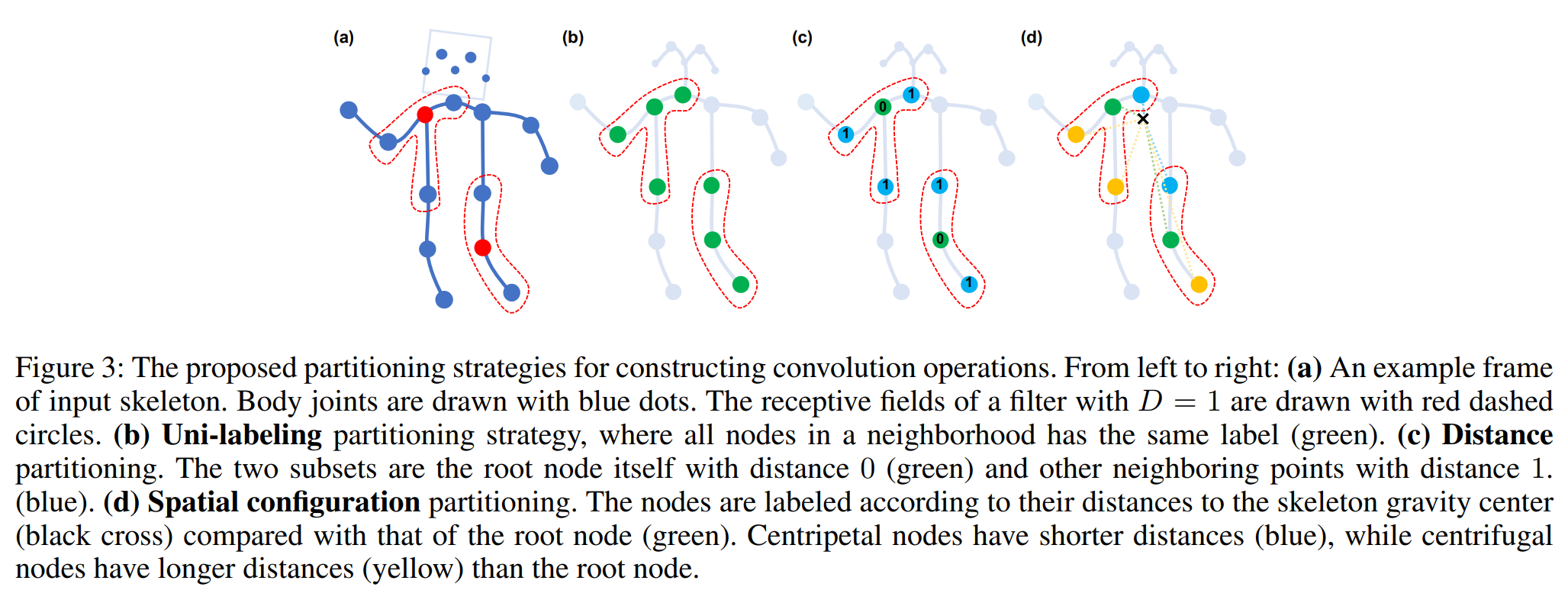
- 그래프 관계: 각 joint마다 인접한 spatial, temporal joint set들을 분할
- Unilabeling: same label
- Distance: root node (0), neighbor nodes (1)
- Spatial configuration: gravity center에서의 거리에 따라서 (0, 1, 2)
[그래프 관계짓는 방법]
- Implementation
- ST-GCN
- Kipf and Welling method [2]
- For each A, including learnable weight matrix M (initialized as all-one matrix)
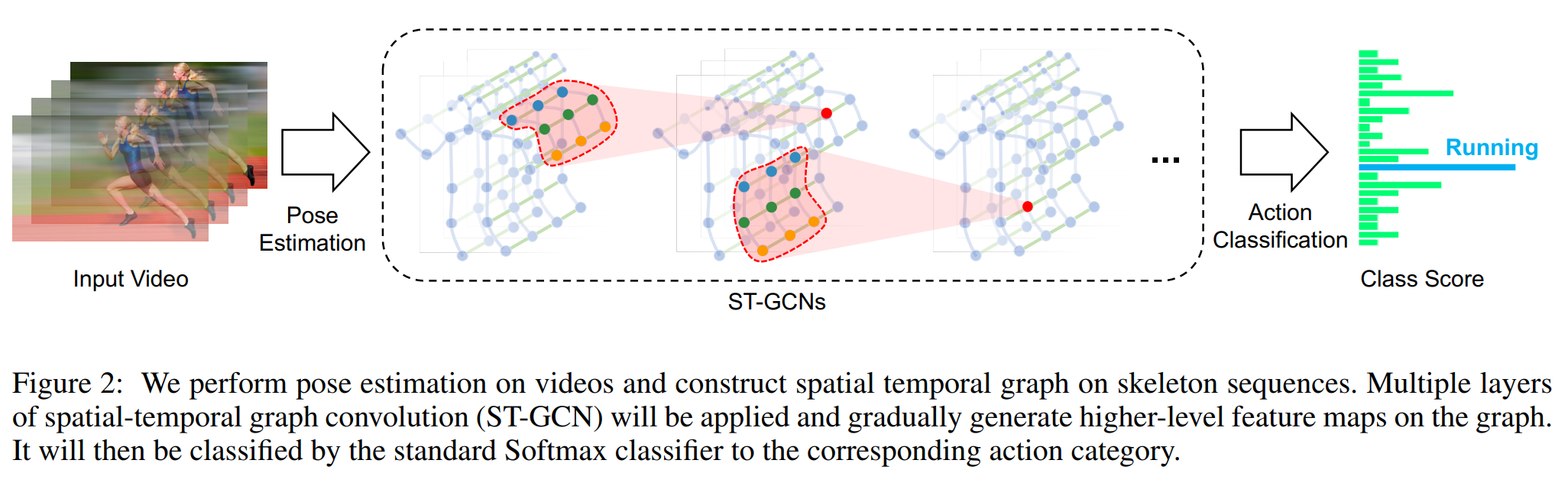
- Architecture
- Input: (3, 300, 18, 2) tensor, (#coordinates + confidence, #frames, #joints, #person)
- Batch normalization, 9 ST-GCN (ResNet mechanism + dropout, 64/64/64/pooling/128/128/128/pooling/256/256/256 channels)
- Output: 256-dim feature vector (applying grobal average pooling), Softmax
- 8 TITANX GPU
- Dataset: Kinetics, NTU-RGB+D
- ST-GCN
[전체 아키텍처]
References
[1] Yan, Sijie, Yuanjun Xiong, and Dahua Lin. “Spatial temporal graph convolutional networks for skeleton-based action recognition.” Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[2] Kipf, Thomas N., and Max Welling. “Semi-supervised classification with graph convolutional networks.” arXiv preprint arXiv:1609.02907 (2016).