[2019 CVPR] Second-order Attention Network for Single Image Super-Resolution
Table of content (short-version) [paper] [github]
Summary
- Super resolution (SR) 논문
- 기존의 SR에 세 가지 모듈 추가
- 아키텍처: NLRG에 의해서 deep feature 추출, upscaling, reconstruction convolution 적용해서 HR영상 출력
[전체 프레임워크]
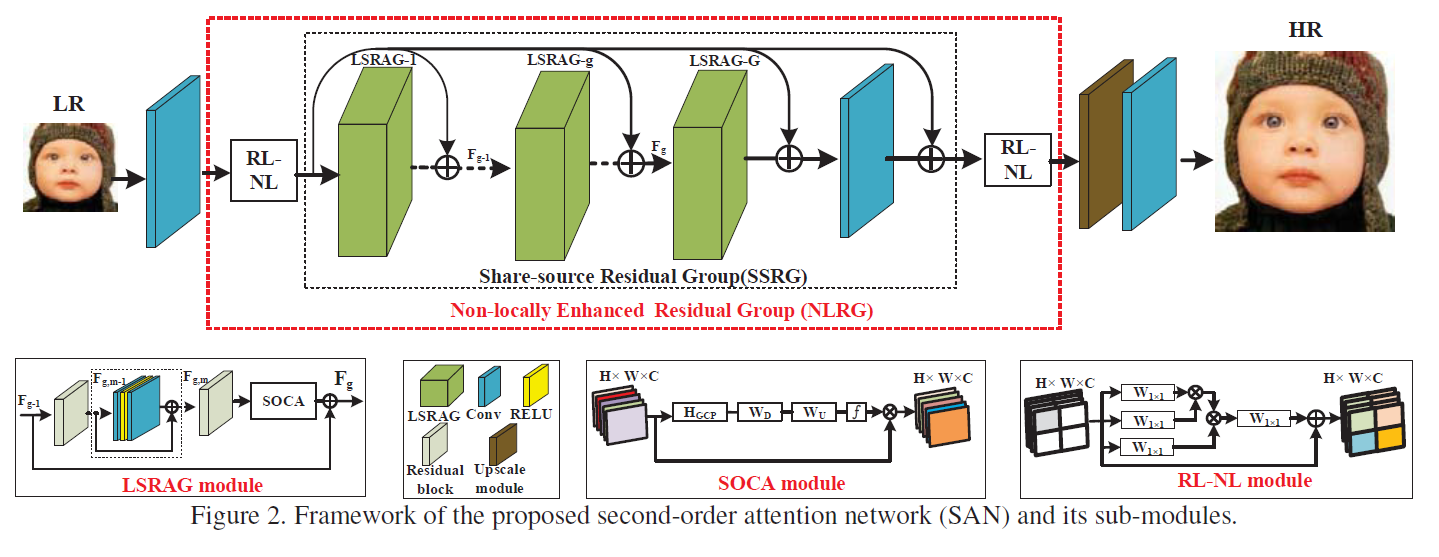
- LSRAG: Residual을 사용하는 variant중에 하나 (큰 기여도는 아님)
- SOCA: Classification 에 사용되는 second-order channel attention을 가져다가 SR에 적용했다.
- Second-order channel attention
- Feature에 대해서 covariance matrix 계산, eigenvalue 구한 다음에, eigenvalue에 큰 쪽에 attention을 더 주는 방식
- 각각의 eigenvalue는 channel의 중요도를 의미
- Alphas는 normalization 관련 term으로 이전 classification 논문과 동일하게 사용
- Second order인 이유는 covariance matrix를 사용하기 때문
- Eigenvalue 구할 때 트릭이 있다.
- Second-order channel attention
- RL-NL: 영상을 4등분하고 각각에 영역에 대해서 non-local module 적용
- 4등분 하는 이유?
- 영상 내에서 거리가 너무 멀어지면 내용이 다른 부분이 있을 수 있어서
- but, 실제로 해보니까 영상의 해상도가 너무 크기 때문에 영역별로 하지 않았나)
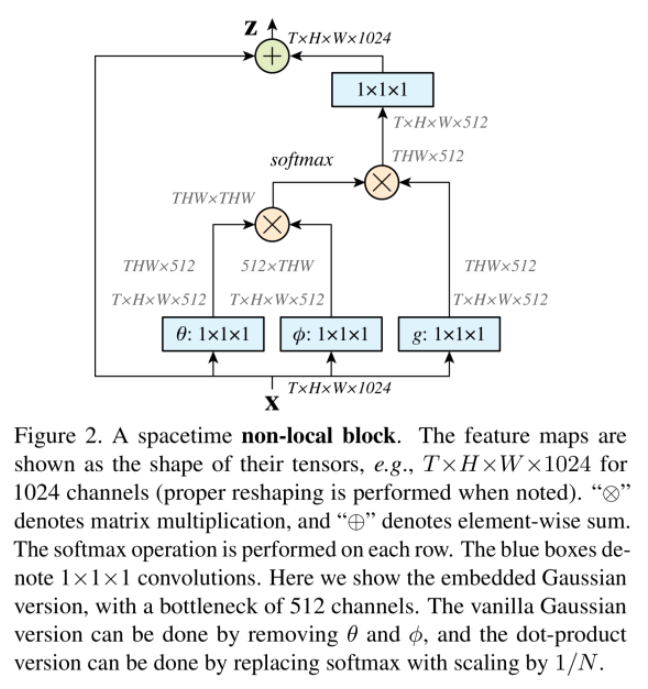
- Non local module이란? ([2] 참고)
- 원래는 classification을 위해 연구된 것
- Local operator(conv, pool)과 달리 영상 전체를 보는 것
- 영상 전체 내에서 서로 비슷한 영역을 고려한 모듈
- 입력된 feature에 대해서 연산을 통해 feature의 차원을 우선 줄인다.
- 이것을 다시 reshape, 공간적으로 관계(THWxTHW)를 고려할 수 있는 매트릭스 생성
- 이를 통해 현재 feature에 공간적으로 비슷한 성분을 고려한 feature 재 생성 가능 (입력 출력 특징 크기 동일)
- 4등분 하는 이유?
[Non-local module]
- 성능
[Ablation study]

[SR 성능 비교]

References
[1] Dai, Tao, et al. “Second-order Attention Network for Single Image Super-Resolution.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[2] https://blog.lunit.io/2018/01/19/non-local-neural-networks/