[2019 CVPR] SCOPS: Self-Supervised Co-Part Segmentation
Table of content (short-version) [paper] [github]
Summary
- Co-part segmentation 논문
- Image recognition 분야는 deformation이 잦으며 part 정보를 이용하면 deformation 강인할 수 있다.
- 여러가지 part 표현 방식 중에서 part segmentation은 조금 더 fine 정보이다. (but fully supervised 방식은 costly, weakly supervised 필요 - saliency 사용)
[Co-part segmentation 개요]

- 제안하는 논문은 4가지 조건을 가정
- Geometric concentration: 파트내의 픽셀들이 뭉쳐야 한다.
- Robustness to variations: deformation에 강해져야 한다.
- Semantic consistency: classification feature와 part feature와 비슷해야 한다.
- Objects as union of parts: 파트들이 모여서 object를 형성해야 한다.
- 3가지 constraint 부여하여 loss 설정
- Geometric concentration loss: part center를 정하고 그 파트 내의 픽셀들이 이와 가까워지도록
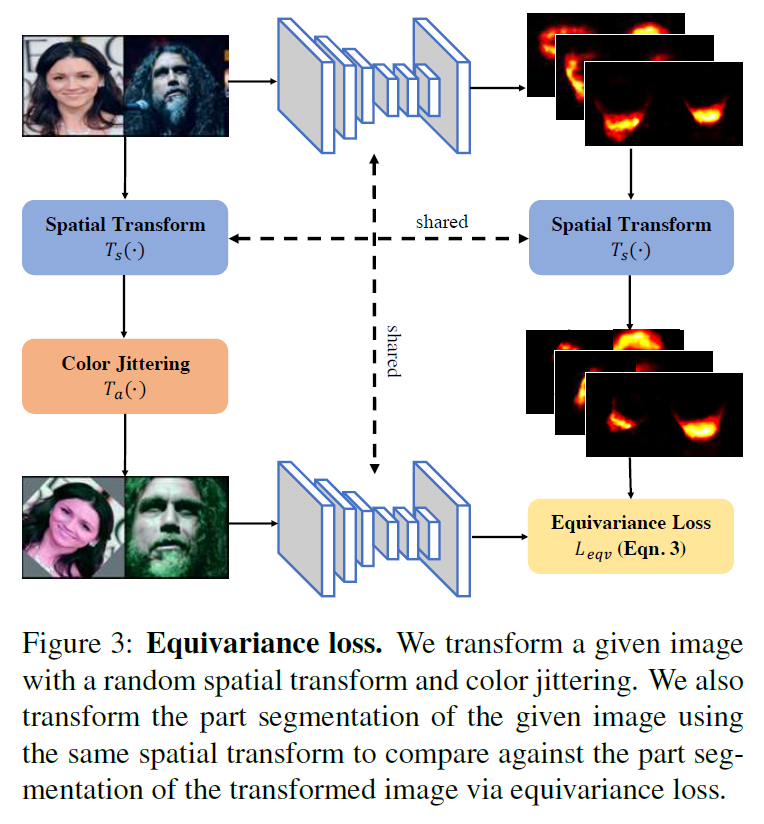
- Equivariance loss: 영상을 물리적으로 변환한 영상의 feature와 원본의 feature를 물리적으로 변환한 것이 동일하도록 학습.
- Spatial: part-center 같도록 하는 loss
- Distribution: KL divergenge distance
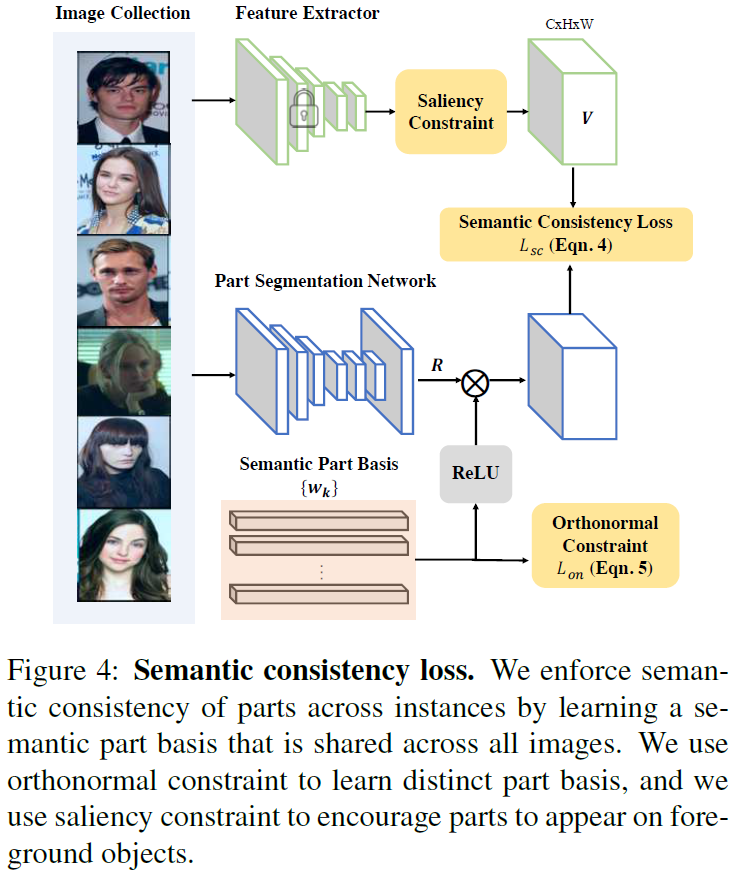
- Semantic consistency loss:
- Classification feature and part feature와 비슷하게
- Part-level orthnormal constraint: part별로 activation되는 spatial 정보 분리
- Saliency constraint: 추가적인 saliency module에 의해서 추출된 것을 이용하여 softmask. object 밖으로 나가면 activation suppression 적용
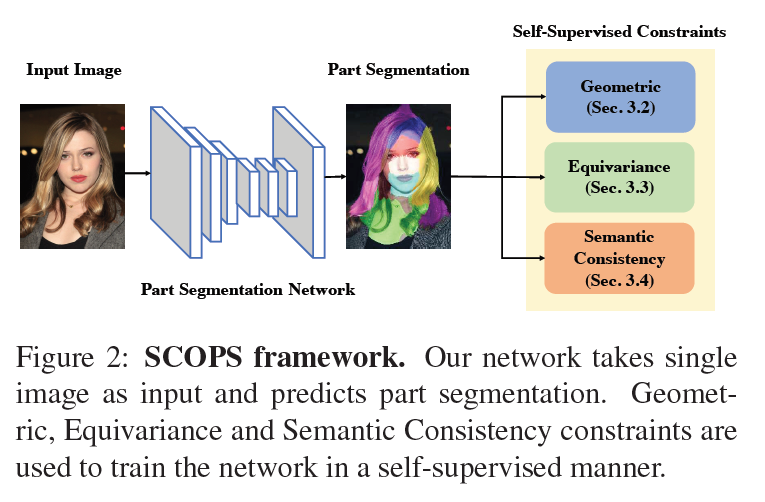
[전체 프레임워크]
[Equivariance loss]
[Semantic consistency loss]
References
[1] Hung, Wei-Chih, et al. “SCOPS: Self-Supervised Co-Part Segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.