[2019 CVPR] Dissecting Person Re-identification from the Viewpoint of Viewpoint
Table of content (full-version) [paper] [github]
Summary
- Viewpoint(pedestrian rotation angle)에 대한 고찰
- 기존에 있는 dataset으로 viewpoint를 분석할 때 문제점
- 데이터의 양이 부족 (사람마다 viewpoint가 한정적, fixed/static)
- 다른 시각적 요소들이 완전이 배제된 채 오로지 viewpoint에 대한 고찰 불가 (실제 데이터셋은 시각적 요소 복합적으로 적용)
- PersonX: large-scale synthetic data engine
- 1266명의 수동으로 제작된 identity
- Controllable (여러가지 시각적 조건 조작 가능)
- 정확한 bounding box (Detection error에 영향을 받지 않음)
- 실험 방법
- PersonX와 다른 기존 데이터셋들에서 reid 방법들이 성능 경향이 어느정도 일치하는지 확인
- Viewpoint가 수동적으로 레이블링된 real-world Market-1203에서 경험적으로 연구
- 연구의 목적
- Training set / Gallery set / Probe set을 디자인 하는 방법 제시
[Viewpoint에 대한 설명]
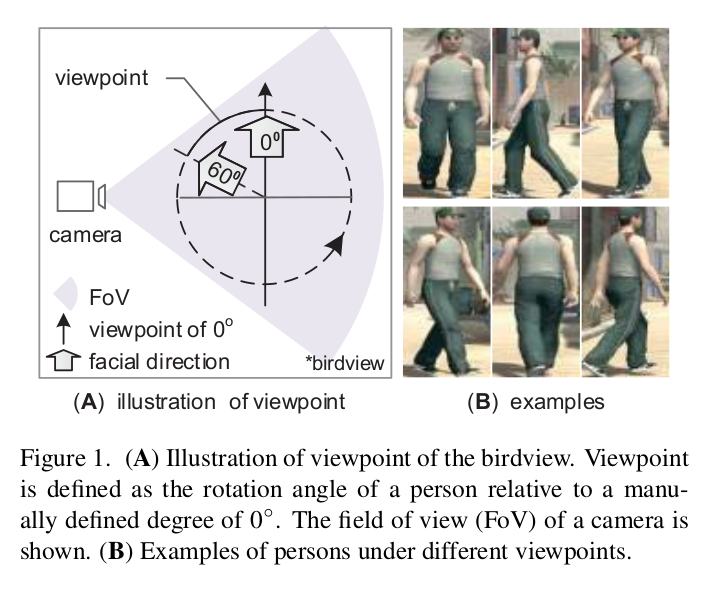
Description
- Summary
- Total number of images: 36 angles 1266 identities 6 cameras
- Resolution: 1024 768 (default), 512 242 (low-resolution)
- Evaluation: training (410 identities) and testing (856 identities, query one image per camera for each identity)
- Identities
- Diversity(1266 identities): skin color, ages, body forms (height and weight), hair styles, clothes (mapped from real-world image), carrying, motion (walking, running, standing, having a dialogue)
- Visual factors
- Viewpoint(36 angles): 36 different angles, 4 orientation (clustered, see the first figure)
- Camera(6 backgrounds): illumination changes (sun light, point light, spotlight, area light), camera (image resolution, projection, focal length, height), background (uniform colors, street scenes)
- (1) white background
- (2) gray background (similar to 1)
- (3) black background (not similar 1)
- (4) street scene
- (5) street scene, different background (similar to 4)
- (6) street scene, different ground color (gray) and shadowed region (not similar to 4)
[PERSONX 데이터셋에서 viewpoint 변화에 대한 예시]

[PERSONX 데이터셋에서 배경/카메라/옷 변화에 대한 예시]

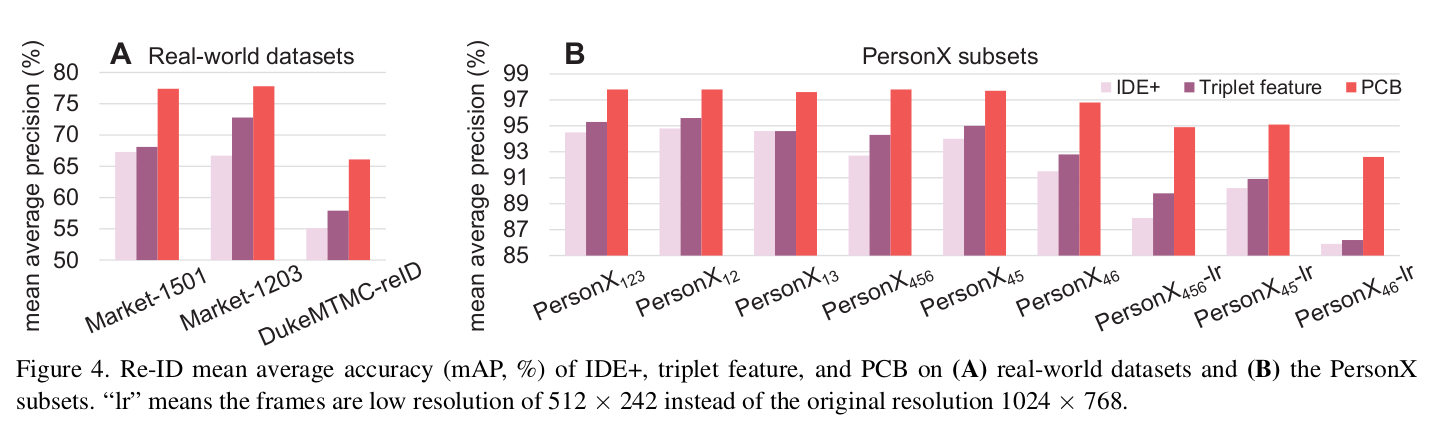
Benchmarking and data validation
- Data validation
- Eliglibility(적격): performance trend is similar to that of real-world dataset
- Purity(순도): High-resolution, normal sunlight, relatively consistent background high accuracy compared to real-world datasets ideal ones for studying the impact of viewpoints
- Sensitivity(민감도): PersonX subsets are sensitive to background complexity (see the second below figure)
- Datasets
- Difficulty
- : color difference
- : background difference
- : more complex background
- : less information
- Existing synthetic datasets
- SyRI, SOMAset
- Difficulty
[PERSONX 데이터셋의 종류]
[데이터셋의 종류에 따른 성능]
Evaluation of viewpoint
- Setting
- Reid 방법: PCB이용
- 평가 방법: 5번 반복한 결과의 평균으로 성능 평가, mAP로 비교
- 평가 데이터셋: Market-1203, ,
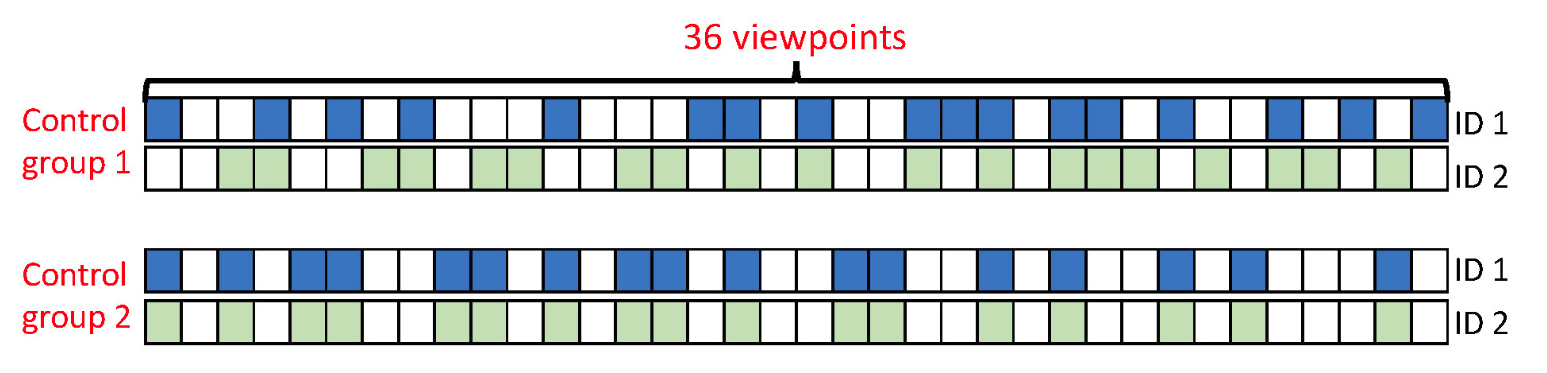
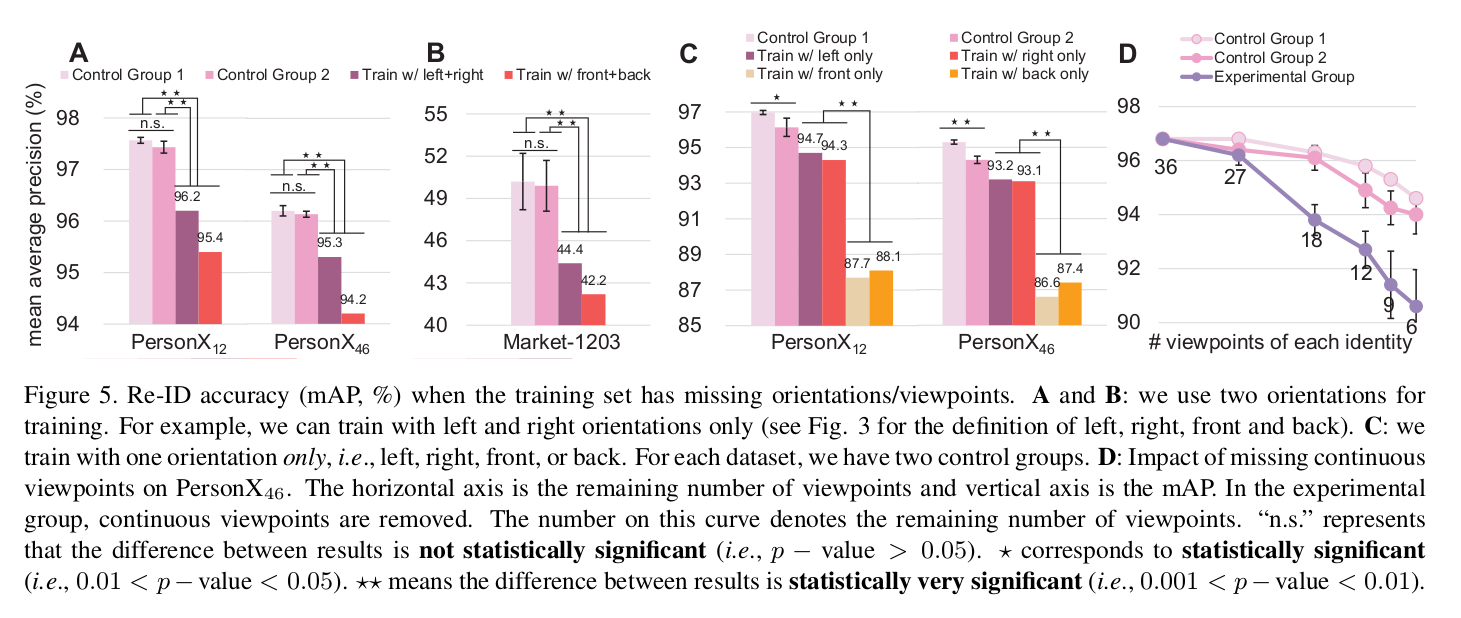
- Control group: random viewpoint
- 1) 학습시 각 ID 마다 무작위로 viewpoint 영상을 삭제 (half or quarter)
- 2) 학습시 무작위로 viewpoint를 제거하여 모든 ID에 대해서 해당 viewpoint만을 학습 (half or quarter)
[Training set에서 control group 예시]
- Experimental group: continuous viewpoint
- One/two orientation 만으로만 학습 (Control
How do viewpoint distributions in the training set affect model learning?
- Summary
- 1) Viewpoint의 전반적인 분포가 학습에 중요하다.
- 성능(control group 1) 성능(control group 2)
- 2) 연속적인 viewpoint가 삭제되는 것보다는 무작위로 삭제되는 것이 낫다.
- 성능(control group 1,2) 성능(Experimental group)
- 3) 제한된 viewpoint만 학습할 수 있다면 left/right를 위주로 학습하는게 낫다.
- 성능(left or right) 성능(front or back)
- Left/right는 보다 general 정보 반영 (color, outfit) 더 중요
- Front/back은 세부 외형 정보 반영 (face, print)
- 4) 학습 데이터셋에서 Viewpoint 정보가 적을수록 성능이 떨어진다.
- 그림 D
- 1) Viewpoint의 전반적인 분포가 학습에 중요하다.
[Training set에서 viewpoint의 부재 실험]
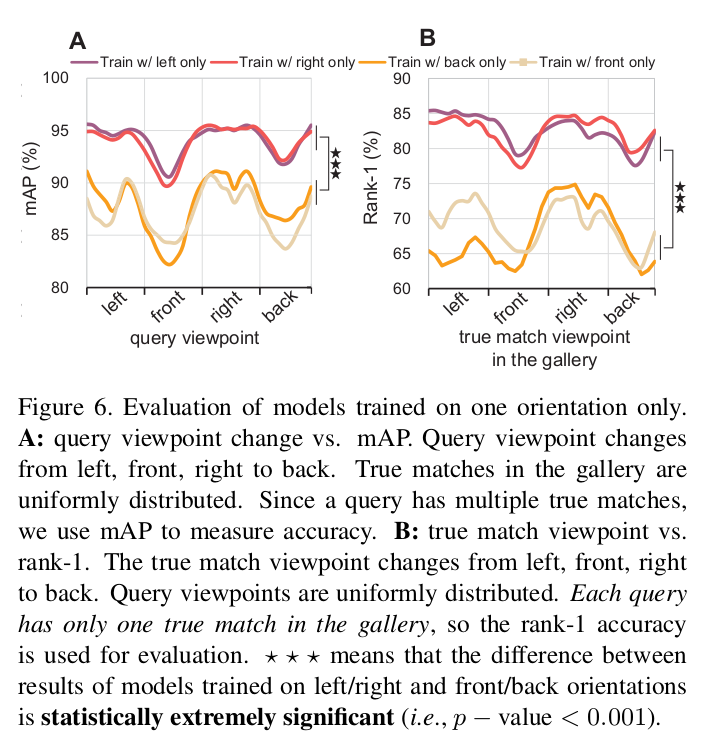
- 추가 실험 (Summary 3 관련)
- A(train:only 1 orientation / gallery: true match viewpoint distributes uniformly)
- Query viewpoint가 위치한 orientation에 따른 성능
- Left/right로 학습하고 해당 viewpoint query에서 성능이 높음
- B(train:only 1 orientation / query: uniform distribution)
- Gallery 내의 true match viewpoint가 위치한
- Left/right로 학습하고 해당 viewpoint gallery에서 성능이 높음
- A(train:only 1 orientation / gallery: true match viewpoint distributes uniformly)
[Training set에서 일부 viewpoint에서만 학습]
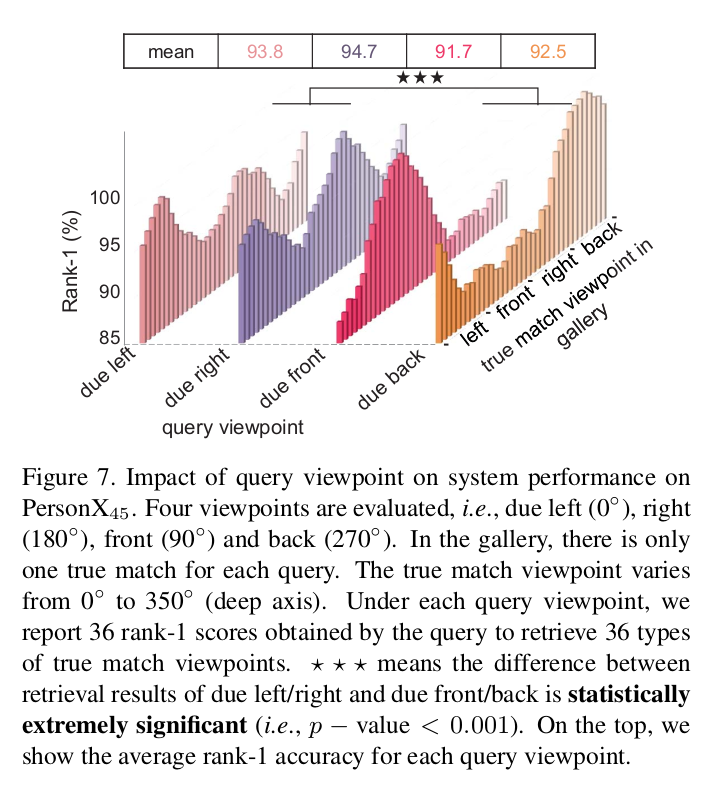
How does query viewpoint affect retrieval?
- Setting
- 모든 viewpoint에서 학습
- Probe는 due 0, 90, 180, 270도
- 에서 학습 및 테스트
- Gallery에 딱 하나의 true match가 있다고 가정 (같은 ID)
- 하나의 probe마다 총 36번의 실험 수행 (true match의 view point 36가지)
[Query 실험에서 true match 예시]

- Summary
- 1) Query와 true match가 비슷한 방향의 viewpoint를 갖을 수록 성능이 높음(left-right, front-back은 어느정도 호환)
- True match의 viewpoint가 query와 동일할 때 성능 가장 높음 (180도 차이나도 어느정도 높음)
- Viewpoint 차이가 없을 때 illumination과 background 차이에 의해서 성능이 일부 하락함
- 2) 성능(Left/right의 viewpoint를 갖는 query) 성능(front/back의 viewpoint를 갖는 query)
- 평균 성능은 left/right가 front/back에 비해서 높음
- 1) Query와 true match가 비슷한 방향의 viewpoint를 갖을 수록 성능이 높음(left-right, front-back은 어느정도 호환)
[Query의 viewpoint 변화에 따른 성능]
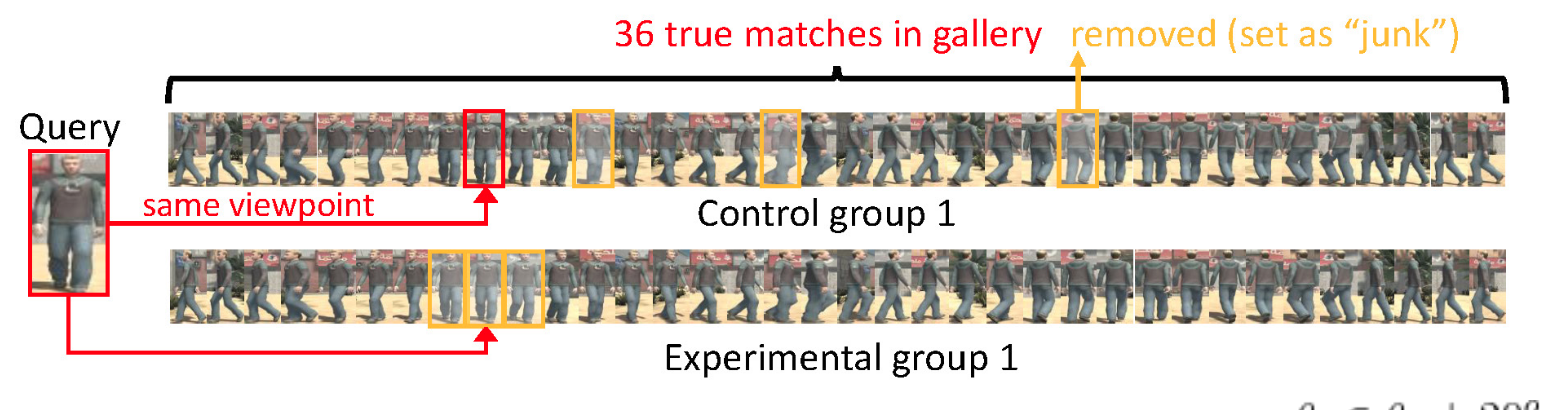
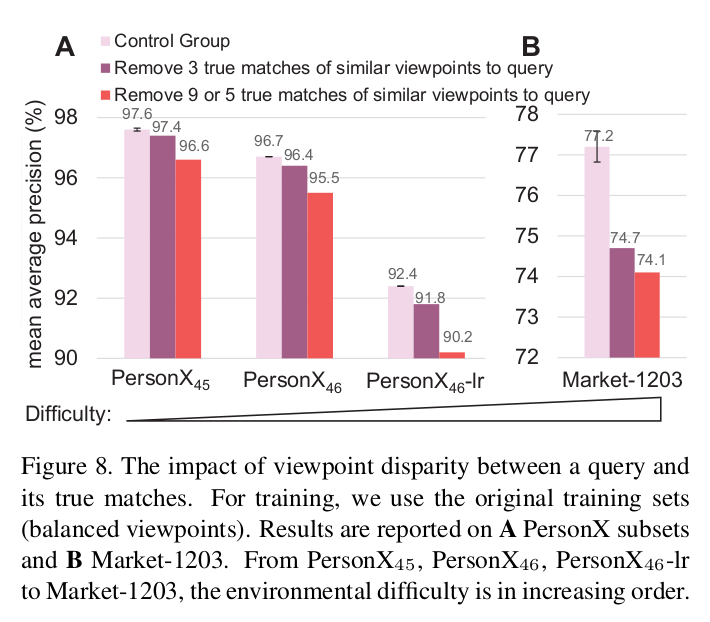
How do true match viewpoints in the gallery affect retrieval?
- Control group
- N개 true match가 random하게 제거
- Experimental group
- Viewpoint가 비슷한 상위 N개 true match 제거
[Gallery 실험에서 control group, experimental group 예시]
- Summary
- 1) Query에 해당하는 gallery의 true match가 다른 viewpoint인 경우 query의 viewpoint와 비슷한 viewpoint를 갖는 다른 사람으로 매칭될 가능성이 높다.
- 성능(control group 1,2) 성능(Experimental group)
- 2) 환경이 악화(complex background, extreme illumination, low resolution)되면 이런 문제가 더 크게 발생한다.
- 성능() 성능()
- 1) Query에 해당하는 gallery의 true match가 다른 viewpoint인 경우 query의 viewpoint와 비슷한 viewpoint를 갖는 다른 사람으로 매칭될 가능성이 높다.
[Query와 true match사이에 존재하는 viewpoint disparity의 영향]
- 추가 실험
- 1) 첫 줄의 경우 gallery에서 similar viewpoint가 있는 경우
- 높은 확률로 true match가 rank 1
- 이를 제거하면 비슷한 viewpoint를 가진 false match들이 매칭
- 2) 2,3,4줄의 경우 gallery에서 similar viewpoint가 없는 경우
- 비슷한 viewpoint를 가진 false match들이 매칭
- viewpoint가 차이나는 true match는 낮은 ranking
- 1) 첫 줄의 경우 gallery에서 similar viewpoint가 있는 경우
[Market-1203에서의 gallery 실험 예시]

References
[1] Sun, Xiaoxiao, and Liang Zheng. “Dissecting Person Re-identification from the Viewpoint of Viewpoint.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.