[2019 CVPR] Unsupervised Person Re-identification by Soft Multilabel Learning
Table of content (full-version) [paper] [github]
Summary
- Unsupervised person REID 분야 (sup reid는 scalability 문제 있음)
- Soft multilabel(SM) learning: (source 도메인의 unlabeled 사람)을 (auxiliary 도메인의 labeled 참조 사람들)과 비교함으로써 soft multilabel을 부여하는 방식 (pseudo label 대신에 real-valued likelihood vector)
[Soft multilabel learning의 컨셉]
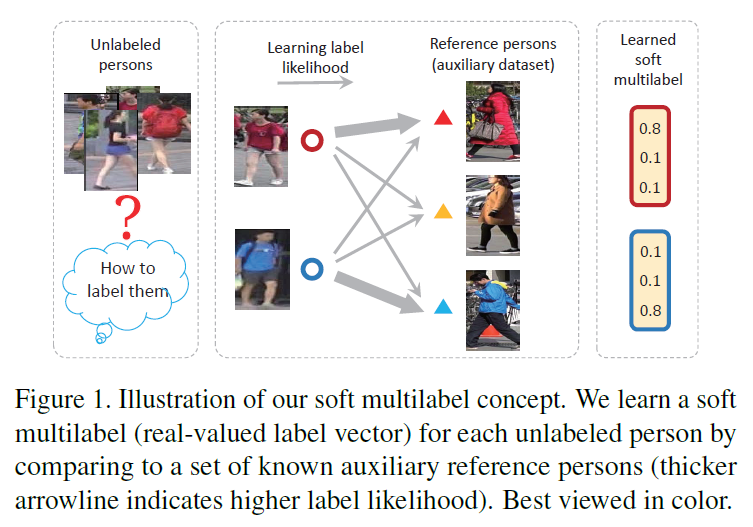
- Deep Soft Multilabel reference learning (MAR) 안에 MDL, CML, RAL 포함
- Soft multilabel-guided discriminative embedding learning (MDL): 시각적 관점과 상대비교 특성에 대한 representation consistancy를 기반으로 soft multilabel-guided hard negative mining을 수행하고, batch마다 unlabeled target DB에 대한 pos/neg set을 확보하여 pos set은 서로 가까워지도록, neg set은 멀어지도록 embedding feature를 학습하는 방법.
- Cross-view consistent soft multilabel learning (CML): 카메라 뷰에 무관한 soft multilabel 학습을 위하여 soft multilabel 분포를 일치시키는 방법
- Reference agent learning (RAL): 효율적인 soft multilabel 학습을 위해 joint feature embedding 학습 (Reference DB에서 reference agent의 차별성과 대표성, feature embedding의 차별성, soft multilabel function 유효성, Cross domain 분포 정렬 및 target DB으로 차별성 전이)
Motivation
- 기존의 방법들
- 기존의 unsupervised reid 방법은 시각적 특징의 유사도만을 사용
- 기존에 unsupervised DA을 기반으로하는 방법 중에서, 보조 labeled source 도메인으로부터 분별력있는 지식을 target domain으로 옮기는 방식이 있는데 이는 unlabeled source와 unlabeled target 사이의 도메인 시프트가 발생
- 그리고 일반적인 unsupervised DA에서 사용하는 같은 클래스간의 변환은 reid task와 이와 적합하지 않음
- 본 논문의 방법은 기존의 unsupervised DA 논문들과 다르게 unlabeled target domain의 분별력있는 정보를 캐지 않은채 보조 데이터를 이용
Architecture
[Notation]
| Symbol | Mean |
|---|---|
| unlabeled target dataset (Market1501, DukeMTMC-reID) | |
| unlabeled target image | |
| the number of target images | |
| labeled auxiliary (reference) dataset (MSMT17 #ID-4101, #Img-126441) | |
| reference image | |
| reference person label | |
| the number of reference persons | |
| the number of reference images | |
| reference agents | |
| soft multilabel | |
| soft multilabel function (label likelihood w.r.t. ref. person) | |
| deep feature embedding | |
| soft multilabel agreement |
- 전체 프레임워크: 3개의 loss term (MDL, CML, RAL) 사용
[전체 프레임워크]
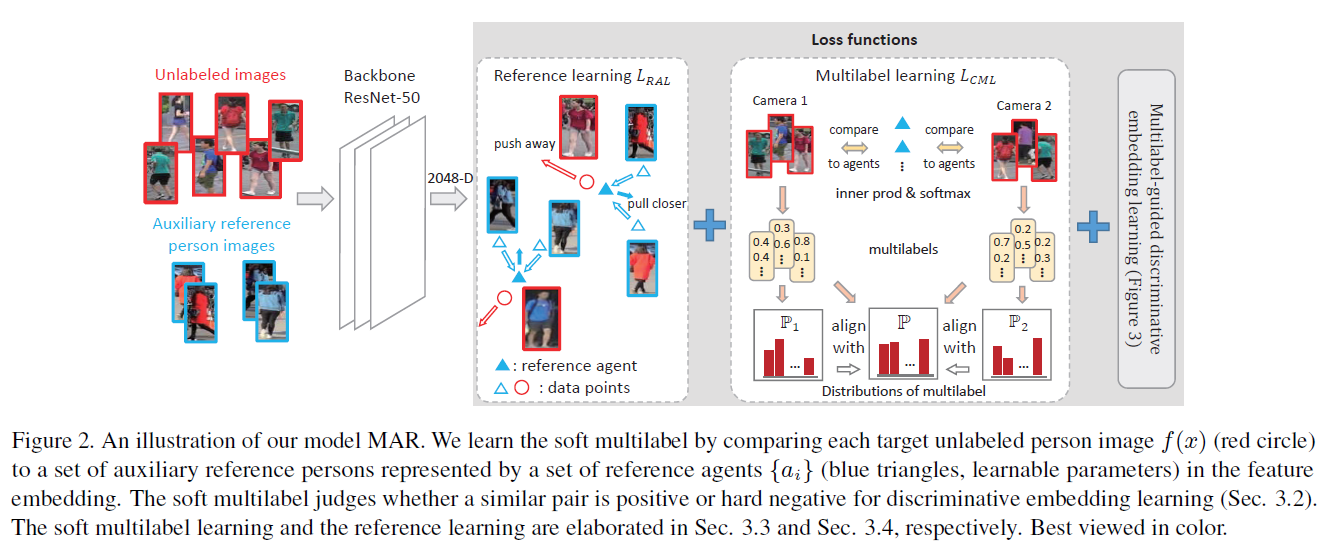
Soft multilabel-guided discriminative embedding learning (MDL)
- 요약
- 학습 대상 (), 필요한 데이터 (positive/negative set from , reference agents )
- Soft multilabel-guided hard negative mining 적용 이후에 unlabeled target domain에서 positive set은 서로 가까워지도록, negetive set은 멀어지도록 embedding feature를 학습하는 방법
- Loss function
$$L_{MDL} = -\log \frac{\overline{P}}{\overline{P} + \overline{N}}$$
$$\overline{P} = \frac{1}{|\mathcal{P}|} \sum_{(i, j) \in \mathcal{P}} \exp (-\left \| f(x_i) - f(x_j) \right \|^2_2)$$
$$\overline{N} = \frac{1}{|\mathcal{N}|} \sum_{(k, l) \in \mathcal{N}} \exp (-\left \| f(x_k) - f(x_l) \right \|^2_2)$$
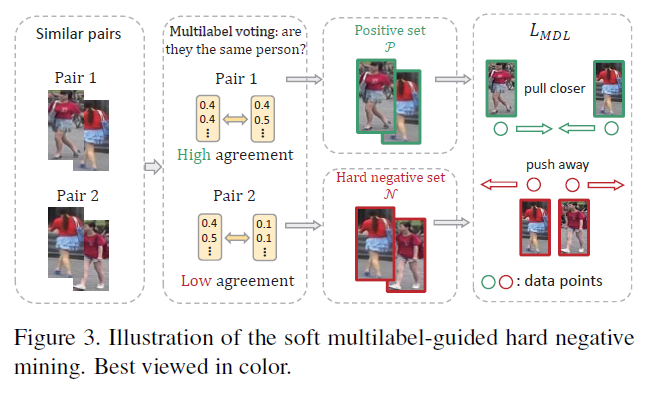
- SM-guided hard negative mining (아래 첫 번째 그림 참고)
- Unlabeled target 도메인에 대한 분별력있는 embedding feature 을 학습하는 방식
- Unlabeled target pair 에서 시각적 특징 과 soft multilabel agreement 을 보고 similarity consistency를 분석
- 시각적으로 서로 유사하지만 (i.e., ) soft multilabel agreement이라는 다른 관점이 서로 다르다면 (i.e., ) hard negative로 판단하고 두 관점 모두에서 영상이 비슷하면 positive set으로 판단
- 한 batch (=368) 내에서 총 가능한 pair 수를 다음과 같이 표현할 때 (i.e., , 는 한 batch 내에서 unlabeled target image의 수, 한 batch는 무작위로 샘플링한 를 절반씩 구성), positive set와 negative set의 비율은 mining ratio 에 의해서 시각적으로 유사한 pair 중에서 threshold 를 이용하여 조정
- 여기에서 hypersphere leaning을 위해 , 라고 가정 (하지만, 이는 수렴 문제 때문에 초기에는 unit norm constraint 없이 만 가지고 network 학습)
- Hard negative pairs에 대한 예시 (아래 두 번째 그림 참고)
- Soft multilabel reference learning 과정을 통해 잠재적인 fine-grained discriminative 단서를 발견
- 빨간 박스들은 한 쌍의 hard negative pair를 보여줌 (첫 줄 Market1501, 두 번째 줄 DukeMTMC-reID)
- 빨간 박스 오른쪽 그림들은 각각 target image에서 soft label이 가장/두 번째로 높은 reference images들을 가리킴 (MSMT17)
[Soft multilabel-guided hard negative mining]
[Soft multilabel-guided hard negative mining의 결과]

Cross-view consistent soft multilabel learning (CML)
- 요약
- 학습대상 (), 필요한 데이터 ( for each camera view, reference agents )
- 카메라 뷰에 무관한 soft multilabel 학습을 위하여 soft multilabel 분포를 일치시키는 방법
- Loss function (simplified 2-Wasserstein distance)
$$L_{CML} = \sum_v \left \| \mu_v - \mu \right \|^2_2 + \left \| \sigma_v - \sigma \right \|^2_2$$
$$y^{(k)} = l(f(x), \left \{ a_i \right \}^{N_p}_{i=1})^{(k)} = \frac{\exp (a_k^T f(x))}{\sum_i \exp (a_i^T f(x))}$$
- 설명
- 참조 영상과의 비교 특성은 카메라 뷰에 무관하며 오로지 target domain에서 사람의 외형 분포에만 의존적이어야 함
- 다시 말해, target domain에서 각 카메라 뷰의 soft multilabel 분포는 전체 target domain에서 soft multilabel 분포와 일치해야 함 (cross-view consistent)
- 분포 비교를 위해서 KL-divergence를 사용해도 되고 Wasserstein distance를 사용해도 되지만 경험적으로 soft multilabel의 분포가 log-normal 분포(soft multilabel에 log를 취한 것이 normal distribution과 비슷함)를 따른다는 것을 확인하여 계산량이 적은 simplified 2-Wasserstein distance(mean vector, std vector) 이용
Reference agent learning (RAL)
$$L_{RAL} = L_{AL} + \beta L_{RJ}$$
- Agent learning loss (AL)
- 요약
- 학습대상 (), 필요한 데이터(, reference agents )
- 이 loss에 의해서 reference agent를 차별적으로 학습하고 feature embedding에게 기본적인 차별능력을 부여하며 (unlabeled target dataset에서는 label이 없어서 차별성을 얻기 힘듬) soft multilabel function 의 유효성을 암시적으로 강요함
- Loss function
$$L_{AL} = \sum_k -\log l(f(z_k), \left \{ a_i \right \})^{(w_k)} = \frac{\exp (a_{w_k}^T f(z_k))}{\sum_i \exp (a_i^T f(z_k))}$$
- 설명
- 원래 soft multilabel function은 target image와 reference agents를 비교했었지만 여기에선 -th reference image와 그에 해당하는 label 를 가진 reference agent를 비교
- Soft multilabel function의 유효성: 이 loss는 label 에 대한 soft label이 1이 되도록 (i.e., one-hot vector가 되도록) 학습을 지향하며 이는 이상적인 soft multilabel agreement를 생성하도록 유도함 (i.e., reference에서 같은 사람이 입력되면 agreement가 1이 됨, 다른사람이 입력되면 agreement가 0이 됨)
- 초기에 는 충분한 차별능력이 없기 때문에 unit norm constraint 없이 만 가지고 를 통해 network 학습
- 요약
- Reference agent joint embedding learning loss (RJ)
- 요약
- AL 방법은 reference dataset에서만 적용되므로 domain gap이 존재, unlabeled target dataset에 대한 유효성이 검증되어야 함, 따라서 joint embedding 학습이 필요
- 학습대상 (), 필요한 데이터(, , reference agents )
- Loss function
$$L_{RJ} = \sum_i \sum_{j \in \mathcal{M}_i} \sum_{k \in \mathcal{W}_i} (1) + (2) $$
$$(1)\: \left [ m - \left \| a_i - f(x_j) \right \|^2_2 \right ]_+, \qquad (2)\: \left \| a_i - f(z_k) \right \|^2_2$$
$$\mathcal{M}_i = \left \{ j | \| a_i - f(x_j) \|^2_2 < m \right \}, \qquad \mathcal{W}_i = \left \{ k | w_k = i \right \}$$
- (1) 설명
- 서로 비슷한 cross-domain pair가 마진만큼 멀어지도록 (분별력)
- 서로 다른 도메인 사이의 분포의 정렬을 위해 cross-domain hard negative pair를 수집함
- Reference agent마다 시각적으로 비슷한 unlabeled person 를 찾은 다음에 이와 차별성을 갖도록 학습함
- 에서 는 cross-domain pair 차이가 margin보다 작은 후보들 (비슷한 후보들)
- 는 hinge loss (margin에 가까워질수록 loss가 감소하는, margin보다 크면 0)
- 는 Agent-based margin
- (2) 설명
- Reference agent와 해당 label에 대응하는 reference images를 최대한 가깝게 (대표성)
- 에서 는 해당하는 번째 reference agent에 대응하는 reference label index
- 요약
Experimental results
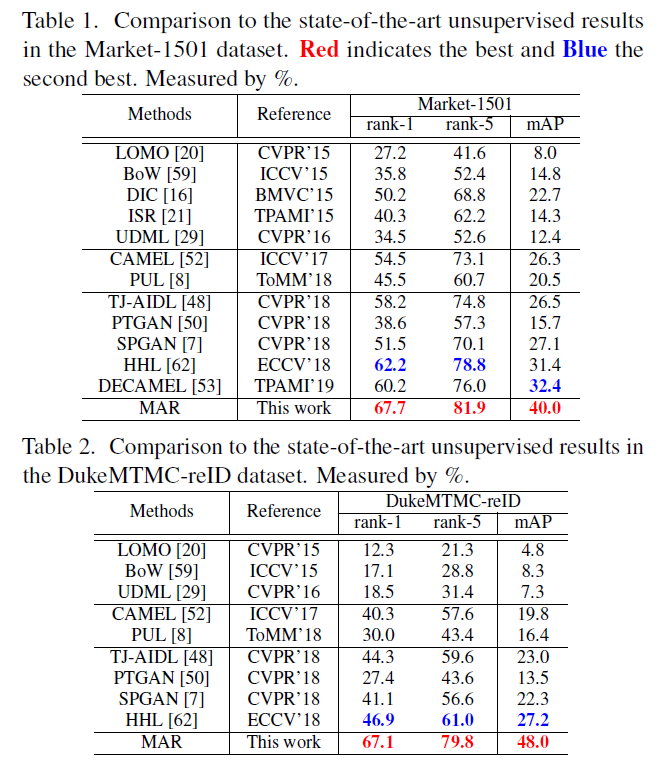
- 성능 비교
- Hand craft: LOMO BoW, DIC, ISR, UDML
- Pseudo label learning: CAMEL, DECAMEL, PUL
- Unsupervised DA: TJ-AIDL, PTGAN, SPGAN, HHL
[Performance comparison (Market-1501, DukeMTMC-reID)]
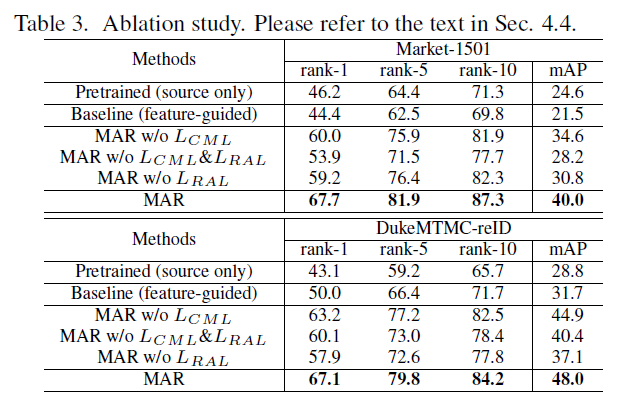
- Ablation study
- Model
- Pretrained: MSMT17(reference dataset)으로 만을 이용해서 기본적인 사람 분별력을 학습
- Baseline: soft multilabel-guided가 아닌 feature similarity guided 방법 (hard negative mining은 많이 비슷하면 pos, 조금비슷하면 hard negative)
- MAR(40.0), pretrained(24.6) 비교: target 정보 부재, soft multilabel-guided hard negative mining의 중요성
- MAR(40.0), MAR w/o CML+RAL(28.2), baseline(21.5) 비교: soft multilabel-guided 방법의 효과 증명
- MAR(40.0), MAR w/o CML(34.6) 비교: cross-view consistency의 중요성 hard negative mining에서 더 정확한 판단가능
- MAR(40.0), MAR w/o RAL(30.8) 비교: valid reference agent의 중요성
- Model
[Ablation study]
- 기타 실험
- Reference 사람 수
- Training data에 있는 사람 수의 두 배 정도 되어야 성능 안정 (즉, MAR는 매우 큰 양의 참조 DB를 요구하는 것은 아니다)
- Hyperparameter 평가
$$L_{MAR} = L_{MDL} + \lambda_1 L_{CML} + \lambda_2 L_{RAL}$$
- , 이 가장 성능이 좋고 비교적 넓은 범위에서 성능 안정
- 기타 파라미터들
- Mining ratio
- 에서 이며 이들은 supp에서 추가 고찰
- Titan X 4대에서 학습 10시간
- Reference 사람 수
References
[1] Yu, Hong-Xing, et al. “Unsupervised Person Re-identification by Soft Multilabel Learning.” arXiv preprint arXiv:1903.06325 (2019).