ALL about vehicle reid (ongoing..)
Table of content
- AI city challenge 2019
- AI city challenge 2018
- Conference paper (CVPR, ECCV, ICCV etc..)
- Others
- Datasets
- Proposed
- References
AI city challenge 2019
(Track 2) City-scale multi-camera vehicle re-identification
[The result of Track 2 in the AI city challenge 2019]
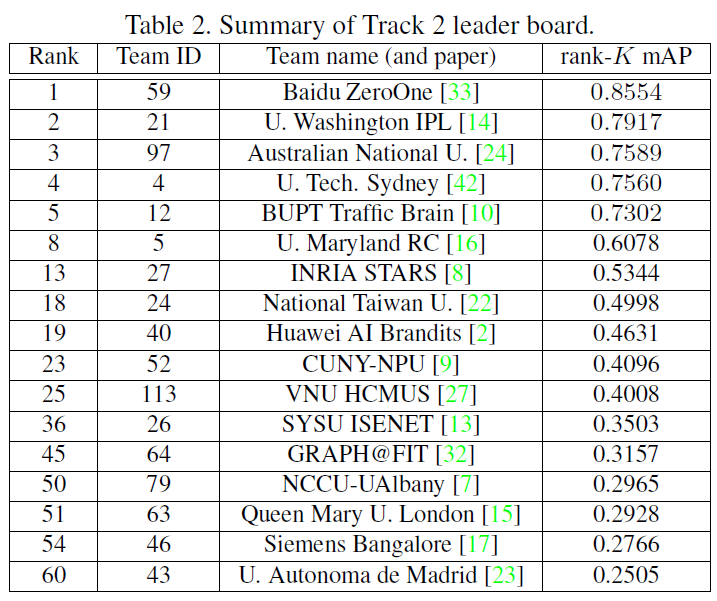
CVPR2019 workshop papers
- (1. Baidu ZeroOne)
- Methods
- Using 3 types of image feature and additional video feature assisted by tracking algorithms
- Image feature (regular training step with training set)
- 1) global feature (linear transform. of the pooling feature of last conv.) + self-attention constrain [1] (for paying more attention to the spatial regions)
- 2) Region feature (multiple granularities network [2] for learning more semantic parts)
- 3) Point feature (extract feature around these keypoint by Keypoint detection [3])
- Video feature (post-processing step that applies at the distance matrix between query feature and gallery feature .)
- Limitation of image-based re-id: Large intra-class variations and similar inter-class appearances
- Multi-camera tracking step can provide each vehicle tracklet
- Each query and gallery image corresponds to a tracklet, so camera info. and duration can be obtained.
- Refine the distance matrix using simple and effective constraints
- If and are some below conditions, we push them.
- 1) condition A: same camera & different ID (This constraint can filter lots of false positives that are similar with a certain query in appearance and direction)
- 2) condition B: same camera (scenario 2) & similar direction (when two direction probability vectors are similar, the corresponding query and gallery are likely to be different vehicles)
- 3) condition C: similar car type (multi-task branches: ID + type classification / trained by attribute-extended CityFlow-ReID [4]) & distance over a certain value (two vehicles with different car types are matched as the same one with a high confidence in camera 35)
- 4) condition D: maximum elapsed time of the gallery and query tracklet is greater than the estimated elapsed time of the camera (time difference must be less than an estimated time window when a vehicle moves from one camera to another)
- Extra group distance
- We can get the group split of all gallery images (by combining the provided the tracklet info. of CityFlow-ReID [4] and the results of multi-camera tracking)
- For each group, find the smallest distance value and add it to all pairs in the group. (weighted sum)
- Re-ranking with k-reciprocal encoding [5]
- Several false positives reoccur after reranking, so constraints are applied again to exclude bad cases
- Training
- CityFlow-ReiD is split into two parts (model selection & parameter learning)
- Initial model (for validation): train with 333-50 identities / evaluate with 50 identities on CitiFlow-ReID
- Final model (for test): train with 30000+ identities (VehicleID [7] + collection from Internet) / fine-tune with 333 identities on CityFlow-ReID & a fine-grained vehicle classification dataset (Cars) [6]
- Data refinement
- Tight bounding box generated by vehicle detector to decrease the interference of background
- Most models are trained on both datasets (original + refined ver.)
- Annotation
- Attribute-extended CityFlow-ReID (8 direction + 5 attributes including color, type, roof rack, sky window, logo)
- Most attributes are not robust in exp. and only the type attribute is used in the final solution
- Model
- The normalized features of all models are concatenated
- Global feature (seresnext101 + resnet101 + resnet152 + hrnet32) + Self-attention constrain (resnet101)
- Region feature (resnet101)
- Point feature (seresnext101)
- Reference
- Multi-camera vehicle tracking and re-identification based on visual and spatial-temporal features
- [1] Jiang, Minyue, Yuan Yuan, and Qi Wang. “Self-attention Learning for Person Re-identification.” BMVC. 2018.
- [2] Wang, Guanshuo, et al. “Learning discriminative features with multiple granularities for person re-identification.” Proceedings of the 26th ACM international conference on Multimedia. 2018.
- [3] Wang, Zhongdao, et al. “Orientation invariant feature embedding and spatial temporal regularization for vehicle re-identification.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
- [4] Tang, Zheng, et al. “Cityflow: A city-scale benchmark for multi-target multi-camera vehicle tracking and re-identification.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- [5] Zhong, Zhun, et al. “Re-ranking person re-identification with k-reciprocal encoding.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
- [6] Krause, Jonathan, et al. “3d object representations for fine-grained categorization.” Proceedings of the IEEE international conference on computer vision workshops. 2013.
- [7] Liu, Hongye, et al. “Deep relative distance learning: Tell the difference between similar vehicles.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Methods
| Overview | Temporal attention |
|---|---|
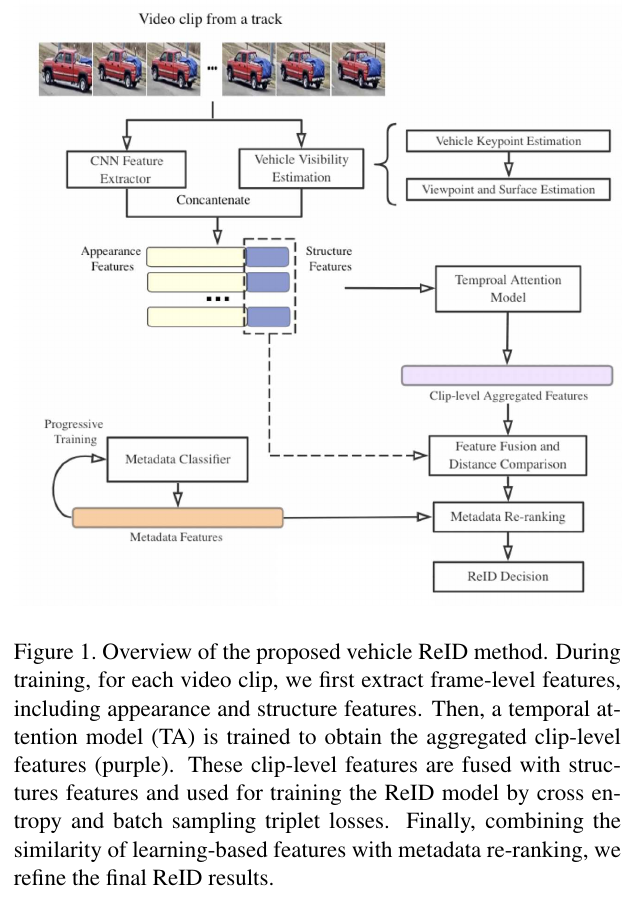 |
 |
- (2. U. Washington IPL)
- Methods
- Frame-level feature extraction
- Feature extrator, ResNet50 (pre-trained on ImageNet, 2048-dim fc layer)
- Keypoint localization (36 points) [1]
- Vehicle orientation feature descriptor
- Estimate surface normal vector
- Concatenate the signed-areas of the projection of all the surfaces and perform L2-norm.
- 36 points 18-dim vehicle orientation feature descriptor
- Viewpoint-aware temporal attention model
- Combine frame-level features using temporal attention modeling [2]
- Train spatial conv (2D) + temporal conv (1D)
- Loss function
- Cross-entropy loss
- Triplet loss
- Batch sample [3] instead of batch hard [4] (to filter sampling outliers)
- Use the multinomial distribution of anchor-to-sample distance to sample data for training
- Metadata classification
- Manually label AIC19 ReID dataset (vehicle type, brand, color)
- Multi-label classification task
- Train by 29-layer light CNN [5] (small kernel size, net-in-net layers, max-feature operation, add one net-in-net layer, so the dimension of fc layer is extended to 2048 rather than 256)
- Metadata distance (create new distance matrix)
- The intuitive idea is that the samples with different metadata classes would have larger distance (use KLD)
- Obtain a new distance by combining the initial ReID distance and metadata distance
- Re-ranking with k-reciprocal encoding
- Based on [6]
- Re-ranking with soft decision boundary
- We generate k-reciprocal nearest neighbor at for the original kNN and then re-calculate the distance between probe and gallery by adding Jaccard distance
- Training
- Use AIC2019 dataset, CompCar dataset [7], self-record traffic video (1 hour each camera, 8 cameras)
- Train a progressive way
- The self-recorded data are fed into the model (pretrained on CompCar and AIC) and samples with high confidence are included into the training set
- The modal is trained and evaluated iteratively until it achieves a good accuracy on the validation set
- Data augmentation
- All images are preprocessed with orientation estimation and the visible parts are cropped (512 512)
- Use various cropped images by visibility estimation
- Frame-level feature extraction
- Reference
- Multi-View Vehicle Re-Identification using Temporal Attention Model and Metadata Re-ranking
- [1] Ansari, Junaid Ahmed, et al. “The Earth Ain’t Flat: Monocular Reconstruction of Vehicles on Steep and Graded Roads from a Moving Camera.” 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018.
- [2] Gao, Jiyang, and Ram Nevatia. “Revisiting temporal modeling for video-based person reid.” arXiv preprint arXiv:1805.02104 (2018).
- [3] Kuma, Ratnesh, et al. “Vehicle re-identification: an efficient baseline using triplet embedding.” 2019 International Joint Conference on Neural Networks (IJCNN). IEEE, 2019.
- [4] Schroff, Florian, Dmitry Kalenichenko, and James Philbin. “Facenet: A unified embedding for face recognition and clustering.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
- [5] Wu, Xiang, et al. “A light cnn for deep face representation with noisy labels.” IEEE Transactions on Information Forensics and Security 13.11 (2018): 2884-2896.
- [6] Zhong, Zhun, et al. “Re-ranking person re-identification with k-reciprocal encoding.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
- [7] Yang, Linjie, et al. “A large-scale car dataset for fine-grained categorization and verification.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
- Methods
[Overall framework]
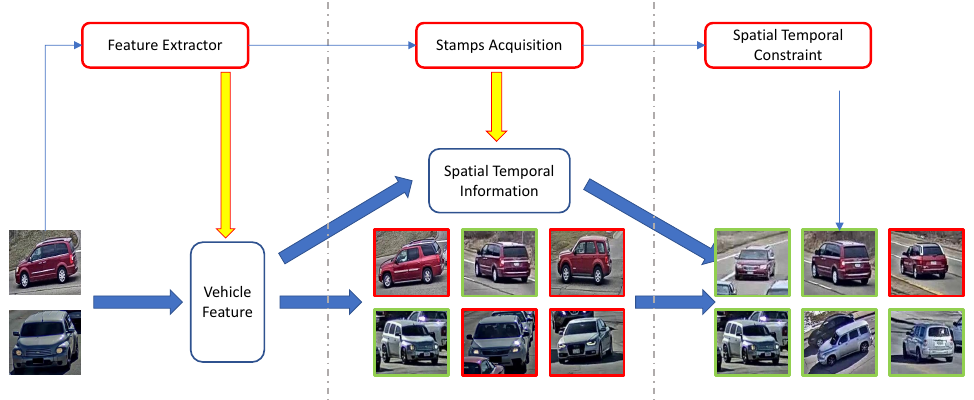
- (3. Australian National U.)
- Methods
- Feature extractor
- DenseNet121
- Baseline: triplet + cross-entropy loss + label smoothing regularization (LSR) [1]
- Ensembling classifiers (normalize and concatenate)
- Baseline w/ hard margin triplet
- Baseline w/ soft margin triplet
- Baseline w/ hard margin triplet + Jitter augmentation
- Query expansion
- Based on image retrieval problem [2,3]
- The basic principle of query expansion lies in that given several vehicles with gradually different perspectives or lighting conditions, and intermediate vehicles can help us to connect them.
- Given the top k(=10) retrieved results of a query image and query itself, we cum-aggregate and re-normalize the feature representations of them
- Temporal pooling for gallery
- The gallery consists of several image sequences
- Use temporal pooling (average pooling) for gallery images during inference (T = 5)
- Stamps acquisition
- There is no location and time of the test images
- Calculate the feature distance between test images and detection patches
- Each test image will have a ranking list
- Take the first detection patch from the list to get its location and time stamp (location stamp is set as the camera location)
- Spatial-Temporal constraint
- Spatio-temporal details can strictly reduce the number of irrelevant gallery images
- There are strict rules for vehicle trajectories rather than human (the vehicles always follow the traffic lanes and the speed remains apprioximately the same)
- As mentioned in [4], there are two key findings
- One vehicle can not appear at multiple locations at the same time
- Vehicles should move continuously along the time
- Location and time stamps are leveraged for the gallery refinement
- During training, we construct a transfer time matrix with the maximum transfer time between each pair of camera (for the cameras that not appeared in the training set, we use the distance between camera pairs to estimate the maximum transfer time)
- During testing, we use it to refine the gallery by ruling out the impossible images (transfer time longer than the corresponding value in the maximum transfer time matrix)
- Training
- Feature learning: IDE+ [5]
- Crop 256 256
- Validate by Veri776 dataset
- Feature extractor
- Reference
- Vehicle Re-identification with Location and Time Stamps
- [1] Szegedy, Christian, et al. “Rethinking the inception architecture for computer vision.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- [2] Arandjelović, Relja, and Andrew Zisserman. “Three things everyone should know to improve object retrieval.” 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012.
- [3] Chum, Ondrej, et al. “Total recall: Automatic query expansion with a generative feature model for object retrieval.” 2007 IEEE 11th International Conference on Computer Vision. IEEE, 2007.
- [4] Wu, Chih-Wei, et al. “Vehicle re-identification with the space-time prior.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2018.
- [5] Zheng, Liang, et al. “Mars: A video benchmark for large-scale person re-identification.” European Conference on Computer Vision. Springer, Cham, 2016.
- Methods
-
VehicleNet, Learning Robust Feature Representation for Vehicle Re-identification
-
Multi-Camera Vehicle Tracking with Powerful Visual Features and Spatial-Temporal Cue
-
Attention Driven Vehicle Re-identification and Unsupervised Anomaly Detection for Traffic Understanding
-
Partition and Reunion, A Two-Branch Neural Network for Vehicle Re-identification
-
Supervised Joint Domain Learning for Vehicle Re-Identification
-
Vehicle Re-Identification, Pushing the limits of re-identification
- Vehicle Re-identification with Learned Representation and Spatial Verification and Abnormality Detection with Multi-Adaptive Vehicle Detectors for Traffic Video Analysis
AI city challenge 2018
(Track 3) Multi-sensor Vehicle Detection and Reidentification
[The result of Track 2 in the AI city challenge 2019]
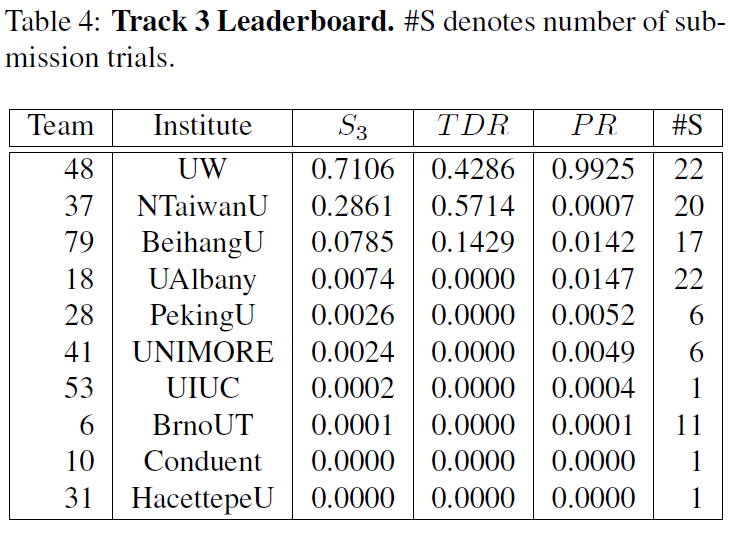
CVPR2018 workshop papers
- Multi-camera vehicle tracking and re-identification based on visual and spatial-temporal features
Conference paper (CVPR, ECCV, ICCV etc..)
- Part-regularized Near-duplicate Vehicle Re-identification (CVPR2019)
- A Dual-Path ModelWith Adaptive Attention For Vehicle Re-Identification (ICCV2019)
- PAMTRI, Pose-Aware Multi-Task Learning for Vehicle Re-Identification Using Highly Randomized Synthetic Data (ICCV2019)
- Vehicle Re-identification in Aerial Imagery, Dataset and Approach (ICCV2019)
- Vehicle Re-identification with Viewpoint-aware Metric Learning (ICCV2019)
Others
- Joint Monocular 3D Vehicle Detection and Tracking (ICCV2019)
- Joint Prediction for Kinematic Trajectories in Vehicle-Pedestrian-Mixed Scenes (ICCV2019)
- Self-supervised Moving Vehicle Tracking with Stereo Sound (ICCV2019)
- Visualizing the Invisible, Occluded Vehicle Segmentation and Recovery (ICCV2019)
Datasets
- VeRi-776 [Project] [paper]
- PKU-VehicleID [Project] [pdf]
- PKU-VD [Project] [pdf]
- VehicleReId [Project] [pdf]
- PKU-Vehicle[Project] [pdf]
- CompCars[Project] [pdf]
- Vehicle-1M[Project] [pdf]
- VRIC [Project] [pdf]
- Veri-wild [project] [pdf]
- CityFlow [project] [pdf]
Proposed
- Focusing point: camera viewpoint change, scale variance, background, occlusion, brightness, car view direction, vehicle landmark, blurry image
References
- https://github.com/knwng/awesome-vehicle-re-identification
- https://www.aicitychallenge.org/
[1]
[2]
[3]
[4]
[5]
[6]