[2019 CVPR] Generalizable Person Re-identification by Domain-Invariant Mapping Network
Table of content (short-version) [paper]
Summary
- 일반화된(universal) re-identification 논문
- source는 train/test다 씀(DB여러개)
- target는 test만 (DB여러개)
- 학습 DB에 없었던 것을 inference (universal DA같은)
- UDA와 다른점은 target domain으로 업데이트할 필요 없음
- Meta-learning의 일종(one-shot/few-shot): memory bank를 이용, target으로 업데이트 할 필요 없음
- 전체 프레임워크
- 갤러리는 특징을 한번 뽑은 다음에 다시 매핑 서브넷을 통해 classifier weight를 생성
- 프로브는 그냥 바로 특징을 생성
- Encoding subnet, mapping subnet, memory bank로 구성
[Domain-Invariant Mapping Network 전체 프레임워크]
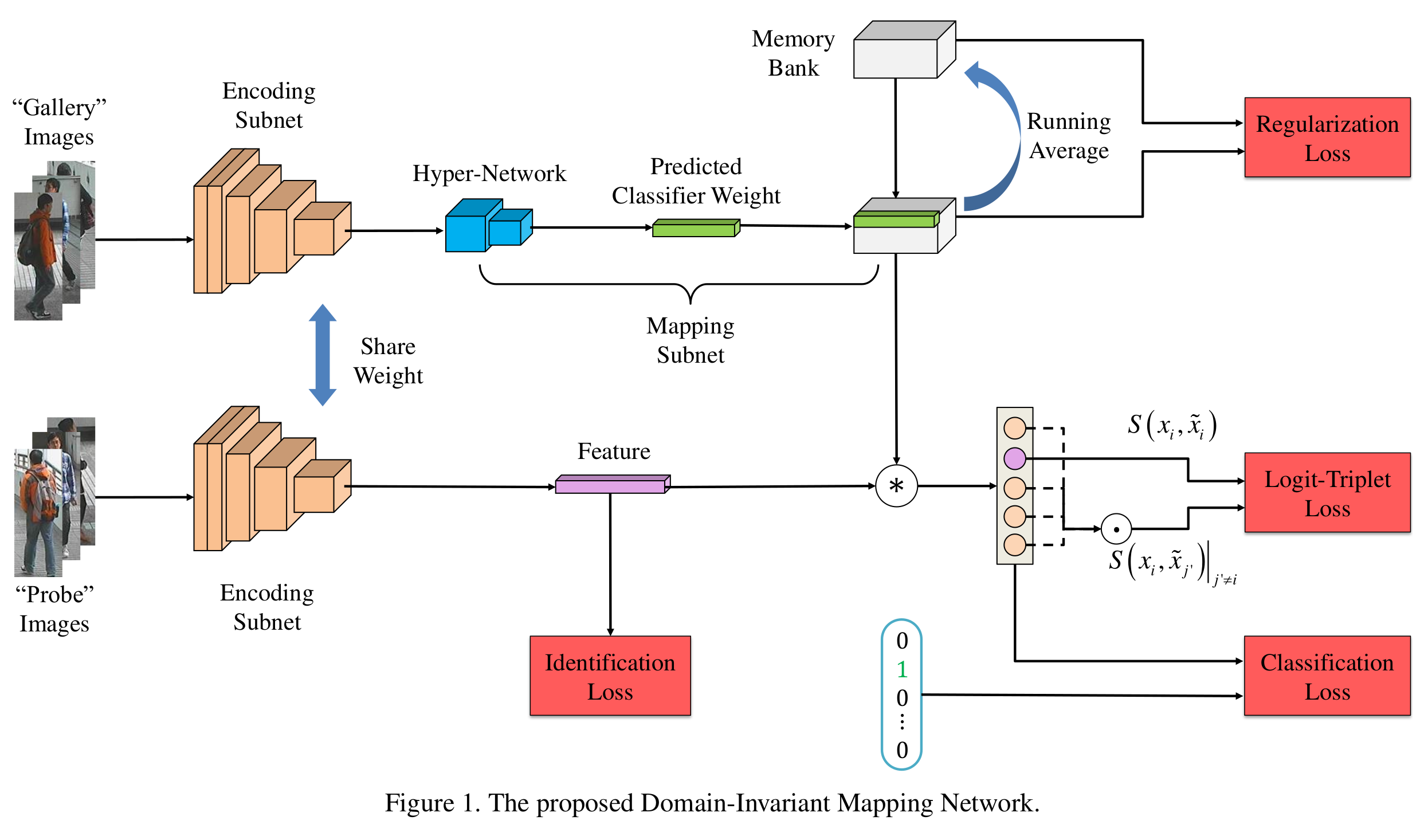
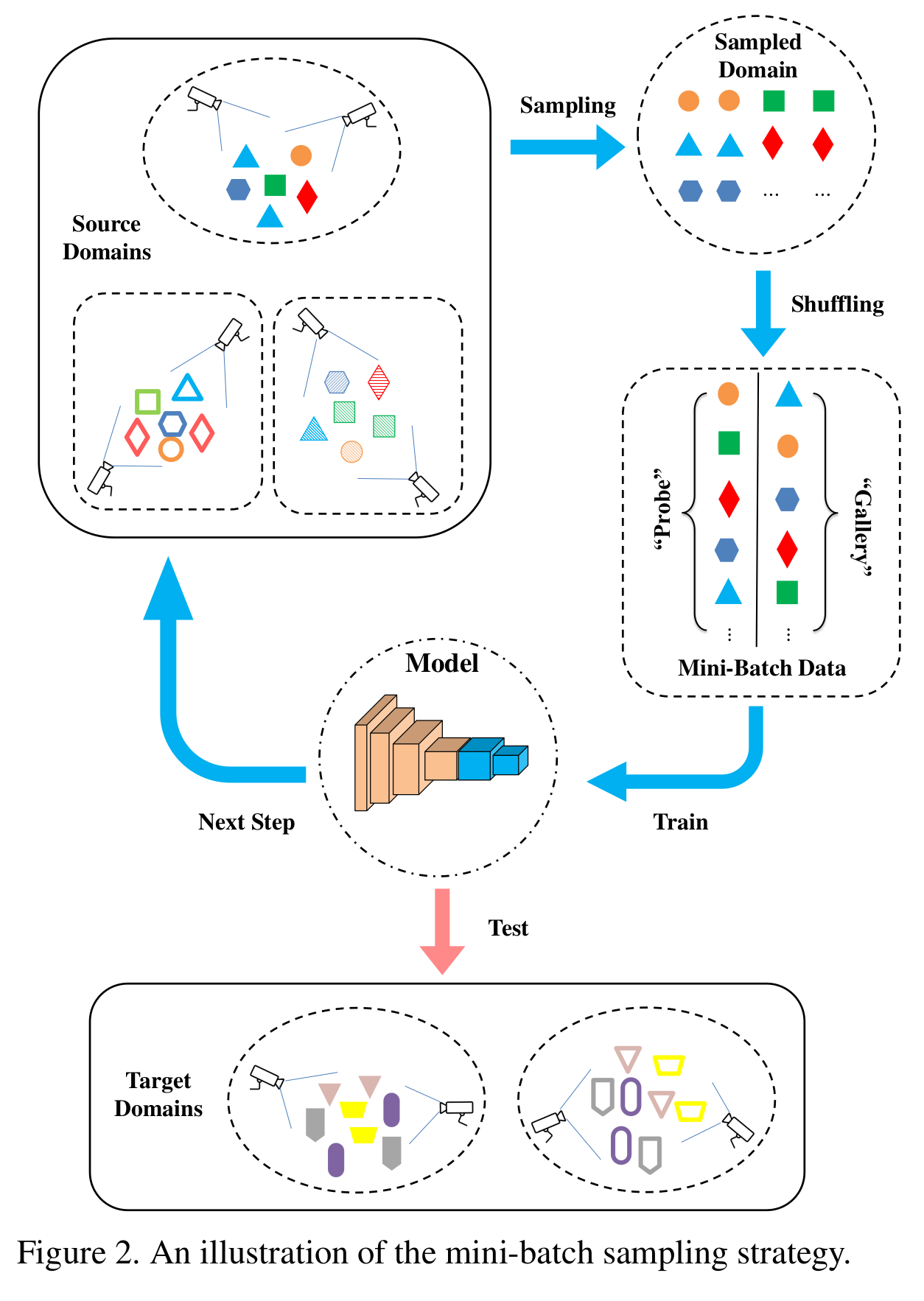
- Encoding subnet: feature extractor, mobileNet (다른것보다 light weight + 성능은 비슷), batch 구성을 다르게 (데이터셋 5개, ID수 18530, 학습 18만) 한번에 학습시키려면 어려워서, 적은 ID로 샘플링, ID 마다 (하나는 갤러리, 하나는 프로브), CE 적용
[Mini-batch sampling 방식]
- Mapping subnet: classifier weight vector 학습 및 생성 FC 몇개 사용해서 생성. 프로브 한개 들어오면 Cb gallery와 비교해서 mapping network 거쳐서 Cb개의 확률이 C개로 키우고(zero padding) 근데 이게 너무 커서 차별성이 떨어진다. 그래서 메모리뱅크 가져와서 C개로 안넘겨도 되게끔. 모든 batch에서는 CbxCb나옴.
- memory bank: D(feature dim) x C(all class) 곱하면 C개가 된다. 증폭 안해도된다. 메모리뱅크는 큰데 원하는 minibatch 부분만 업데이트한다. memory bank를 사용한 결과에 CE loss사용. running average. regularization을 적용해서 안정화. logit-triplet loss.
[DIMN 학습 알고리즘]

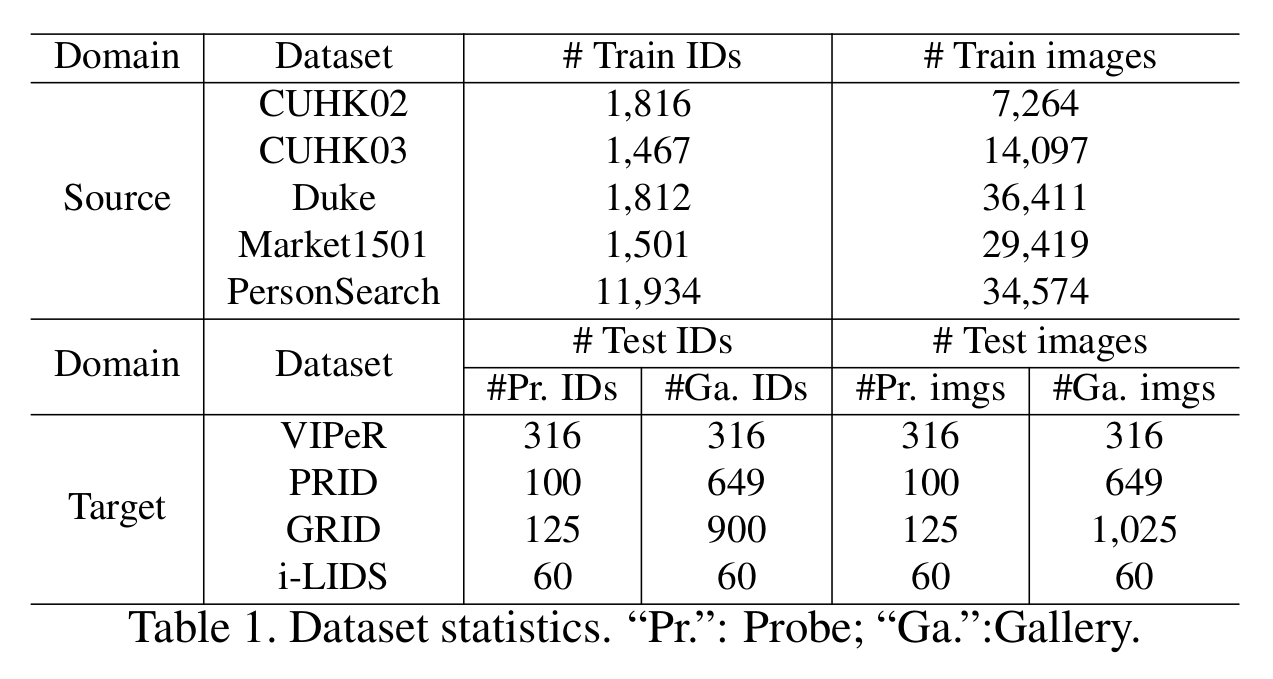
[데이터셋 정보]
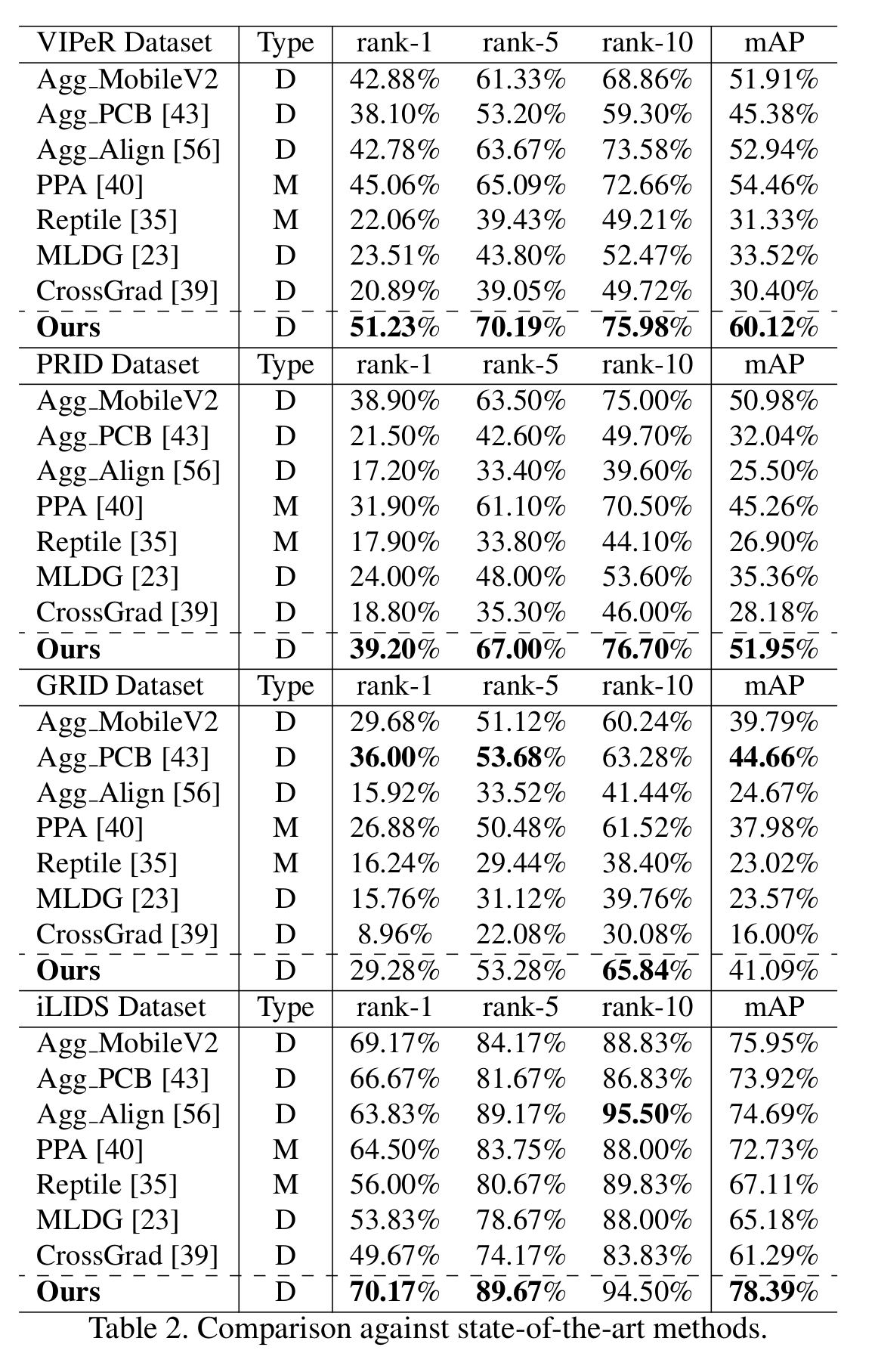
[Performance comparison 1]
[Performance comparison 2]
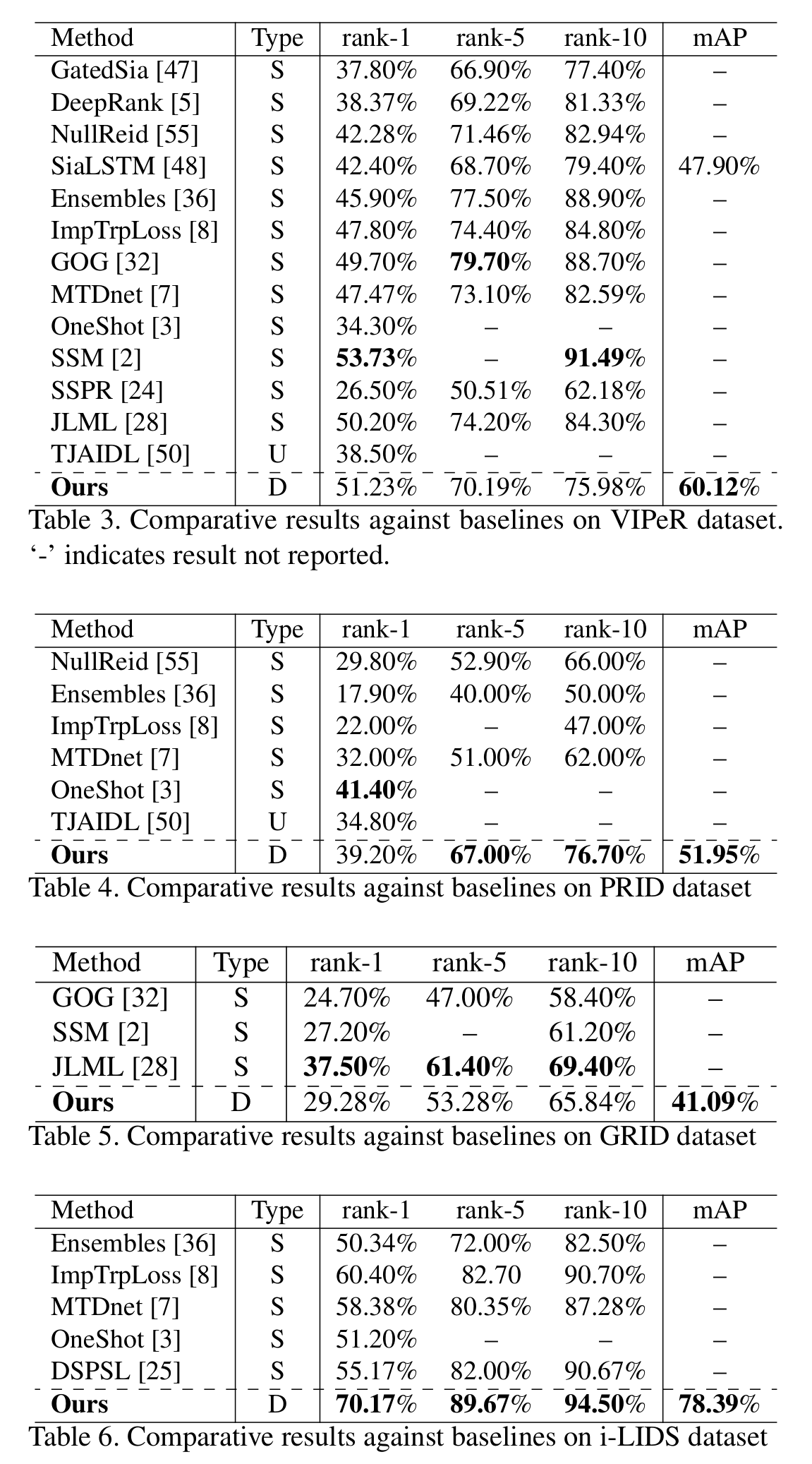
[Ablation study]
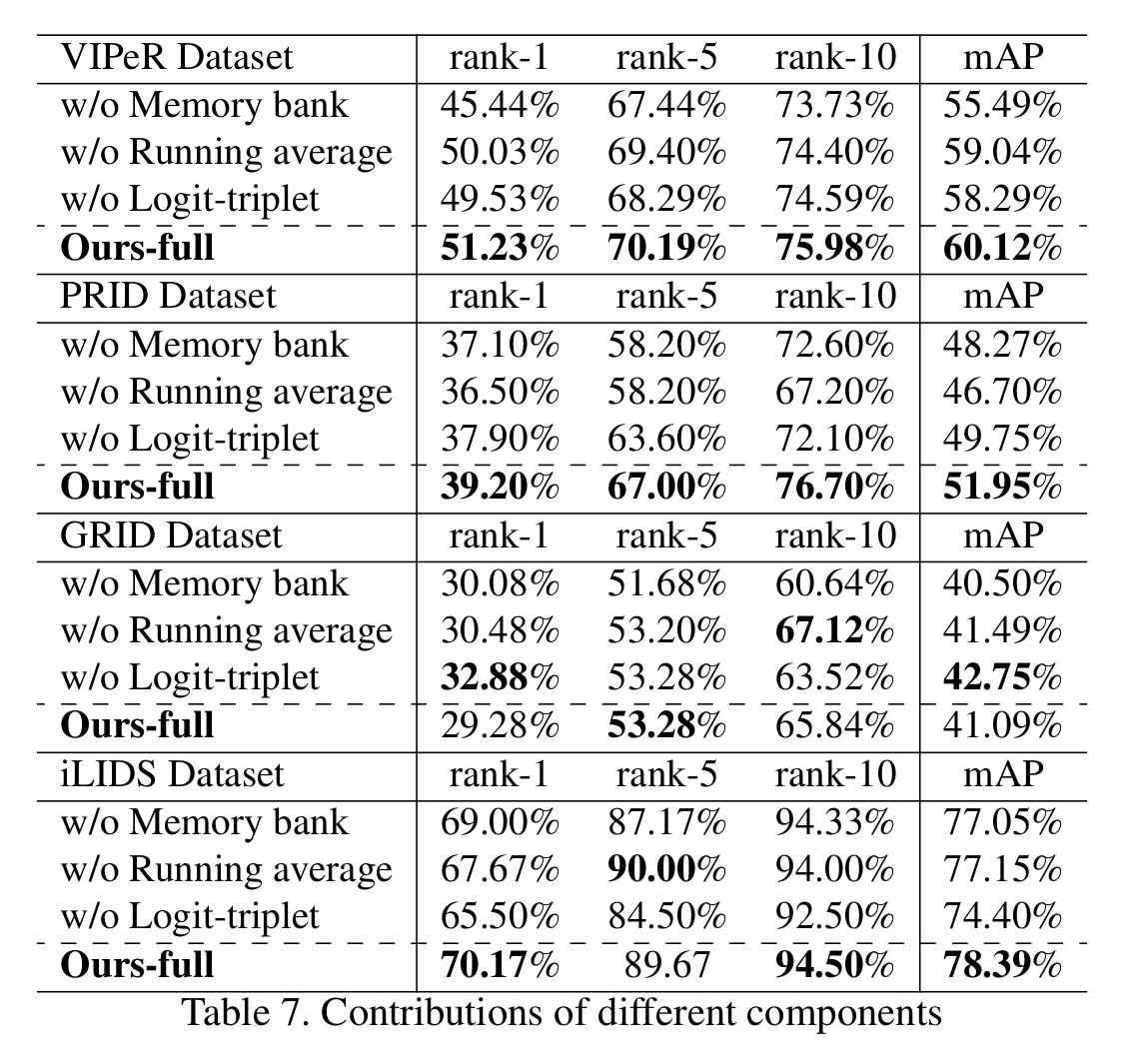
[Few-shot learning 결과]
References
[1] Song, Jifei, et al. “Generalizable Person Re-identification by Domain-Invariant Mapping Network.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.